
标签
04存储器
日期
Place
创建时间
Jan 8, 2026 01:48 PM
概述
问题的提出
为什么要引入Cache
- 在多体并行存储系统中,I/O 设备访存优先于 CPU,造成 CPU“空等” 现象
- 主存与CPU的速度不匹配
- 程序访问的局部性原理
回顾Cache的作用
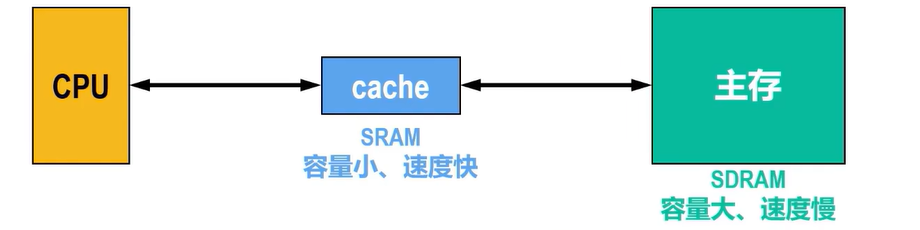
- 主存中一般采用容量大、功耗较小、成本较低的同步动态随机存取存储器SDRAM
- 静态随机存取存储器SRAM的容量小、功耗大、成本高,但其访问速度远高于SDRAM
- 为了提升CPU访问主存的性能,通常会在CPU与主存之间添加一个SRAM作为高速缓冲存储器Cache
- 将主存中经常访问或即将访问的数据,复制一份(调度)到Cache中,使得大部分数据访问都可以在Cache中进行,从而提升系统性能
- main reason:CPU执行的程序具有较强的程序局部性
设置 Cache 就是为了将主存的局部性数据块提前调度到 Cache 中,在较大的概率/命中率保证下,被 CPU 直接访问,而节省了访问主存的时间。
程序局部性
定义:
- 在一段时间内,整个程序的执行仅限于一个较小的局部范围内
- 在一个较短的时间间隔内,CPU 对局部范围的存储器空间频繁访问,而对此地址范围之外的存储空间访问很少,这称为程序(或数据)访问的局部性
- 指令和数据在主存的地址分布不是随机的,而是相对的簇聚,使得CPU在执行程序时,访存具有相对的局部性
- 时间局部性
- 若程序在某个时刻访问了一个存储位置,该位置在未来可能会被多次访问
- eg:程序中的循环结构和调用过程
- 空间局部性
- 若程序访问了某个存储位置,则其附近的存储位置也可能被访问
- eg:程序中的数组、结构体成员、顺序执行的代码块

Cache系统的性能评价
数据访问时间
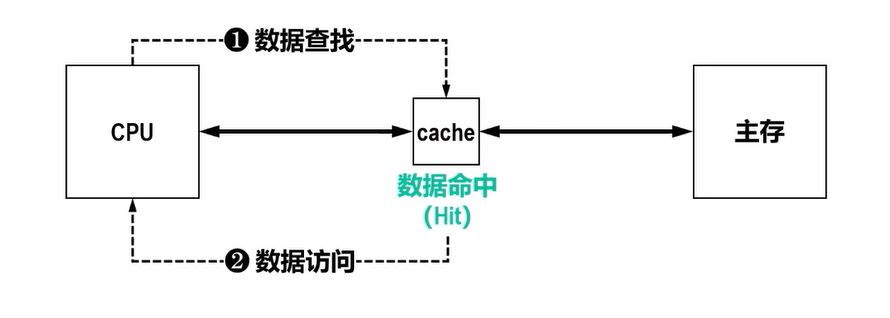
在CPU和主存之间添加了Cache后,CPU不再访问慢速的主存,而是通过字节地址访问快速的Cache
- 数据访问时间
- 命中访问时间tc=Cache内查找时间+Cache访问时间
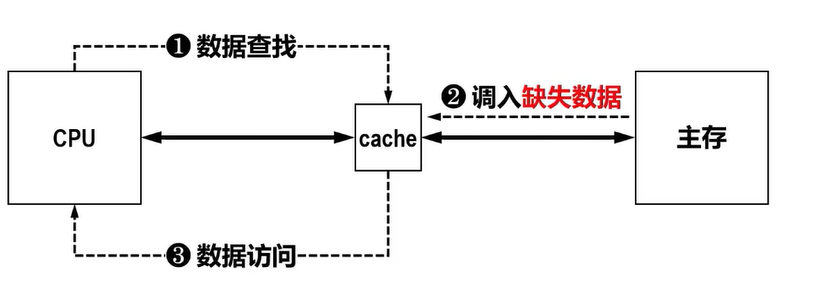
- 缺失补偿=Cache内查找时间+主存访问时间tm(较为漫长)+Cache访问时间
- 由于主存访问时间比其他两部分时间长很多,通常用tm表示缺失补偿
Cache系统的性能评价
- 命中率 某程序运行期间命中Cache的次数为$n_c$,从主存中访问信息的次数为$n_m$,命中率h为: $$h = \frac{n_c}{n_c + n_m}$$
h越接近于1性能越好
1-h称为缺失率
ps:
命中率与Cache的容量与块长相关
一般每块可取 4 ∼ 8 个可编址单位较好,也可取一个主存周期内所能调出主存的信息长度6t'g
- Cache/主存系统的平均访问时间 命中情况下访问时间$t_c$,数据缺失情况下访问时间$t_m$,则Cache/主存系统的平均访问时间$t_a$: $$t_a=ht_c+(1-h)t_m$$
同时访问Cache和主存,若Cache命中则立即停止访问主存
h越接近于1,ta越接近于tc
- 访问效率e $$e=\frac{t_c}{t_a}$$
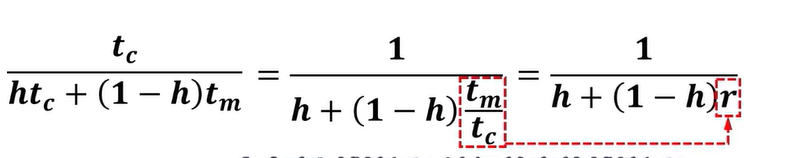
h越接近1,e越接近1
Cache的工作原理
- 数据块的划分
根据程序局部性原理,可以把CPU目前访问的地址周围的部分数据放到Cache中,如何界定周围---将主存的存储空间分块
为了与Cache映射,将主存与缓存都分成若干个块,每块内又包含若干个字,
并使它们的块大小相同
主存与Cache之间以块为单位进行数据交换
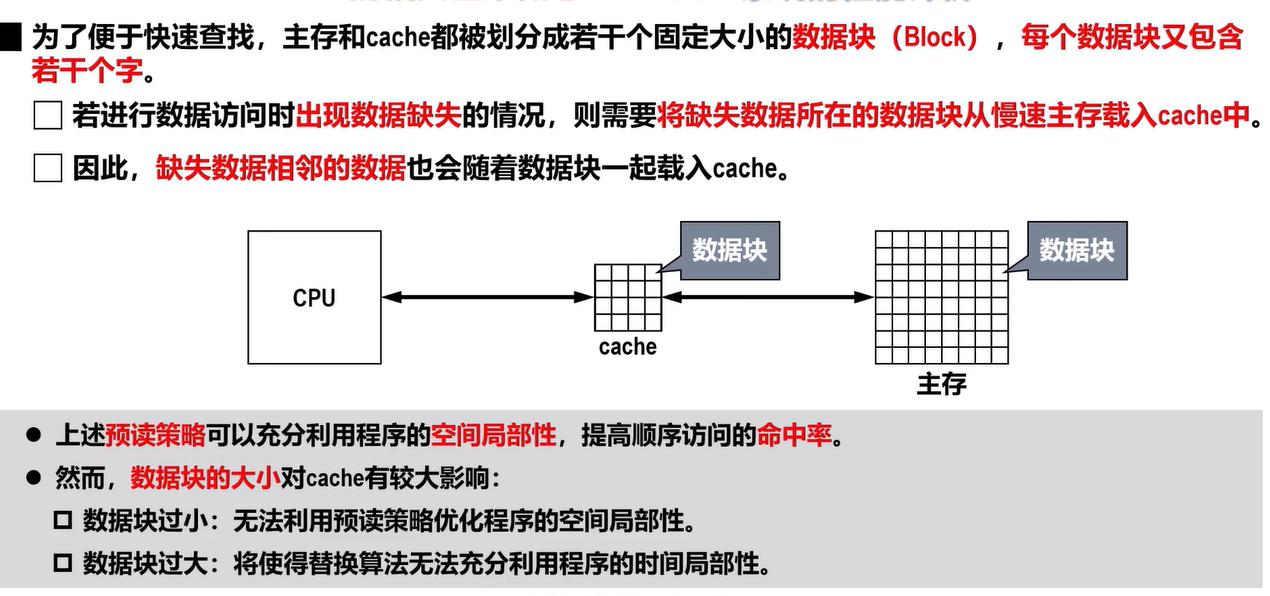
将主存的地址分为两个部分:
高m位表示主存的块地址,低b位表示块内地址
将缓存的地址分为两个部分:
高c位标识缓存的块号,低b位表示块内地址
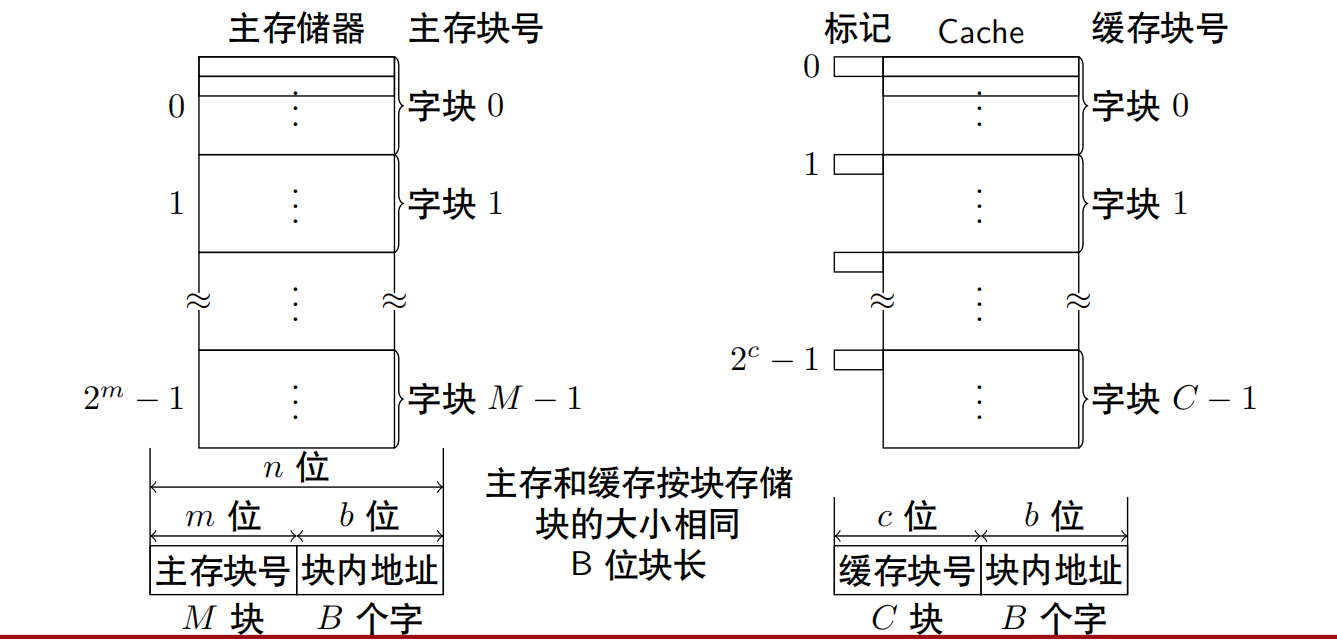
$$
\begin{align}
2^m=M\qquad \text{主存的块数}\\
2^c=C\qquad \text{缓存的块数}\\
C << M
\end{align}
$$
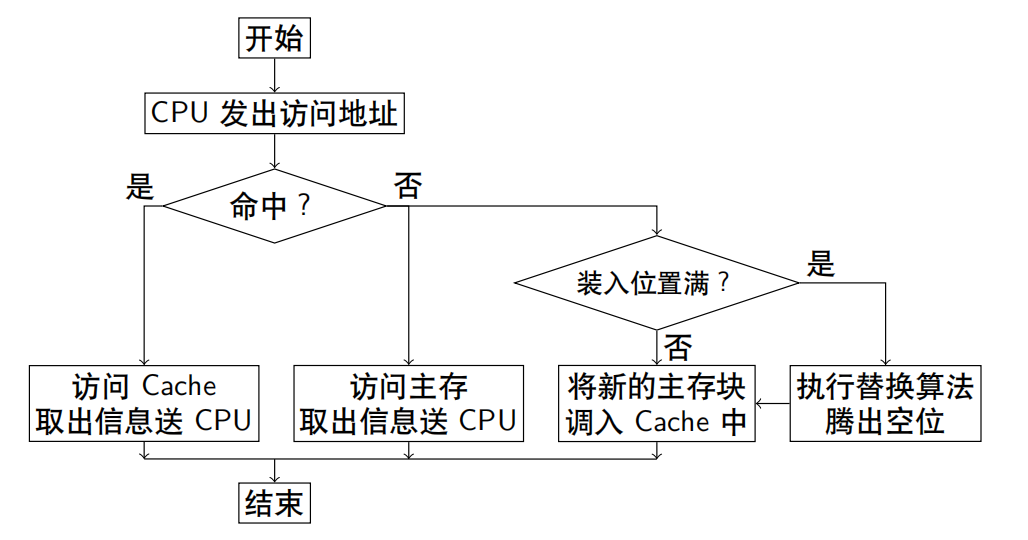
2. 命中与未命中
任何时刻都有一些主存块处在缓存块中,CPU欲读取主存某字时,有两种可能
- CPU访问Cache命中
- 主存块已调入缓存,即可直接访问Cache
- 主存块与缓存快建立了对应关系
- CPU访问Cache不命中
- 主存块未调入缓存
- 主存块与缓存快未建立对应关系
- 若Cache未被装满
- 此刻CPU在访问主存的时候,不仅将该字从主存取出,同时将它所在的主存块一并调入Cache,供CPU使用
- 若Cache已装满
- 已无法将主存块调入Cache中,采用替换策略 由于C<< M,一个缓存块不能唯一地、永久地只对应一个主存块,故每个缓存块设置一个标记用来表示当前存放的是哪一个主存块,该标记的内容相当于主存的编号
- Cache基本结构
- Cache存储体
- Cache存储体以块为单位与主存交换信息
- 地址映射变换机构
- 将CPU送来的主存地址转化为Cache地址
- 替换机构
- 当Cache中内容已满,无法接受来自主存块的信息时,由Cache内的替换机构按一定的替换算法确定应从Cache内移出哪个块返回主存,而把新块调入Cache中 Cache对用户透明的,将主存块调入Cache的任务由机器硬件自动完成
Cache的读写流程
引出实现Cache的关键技术
- 数据查找
- 地址映射
- 替换策略
- 写入策略
Cache的读操作
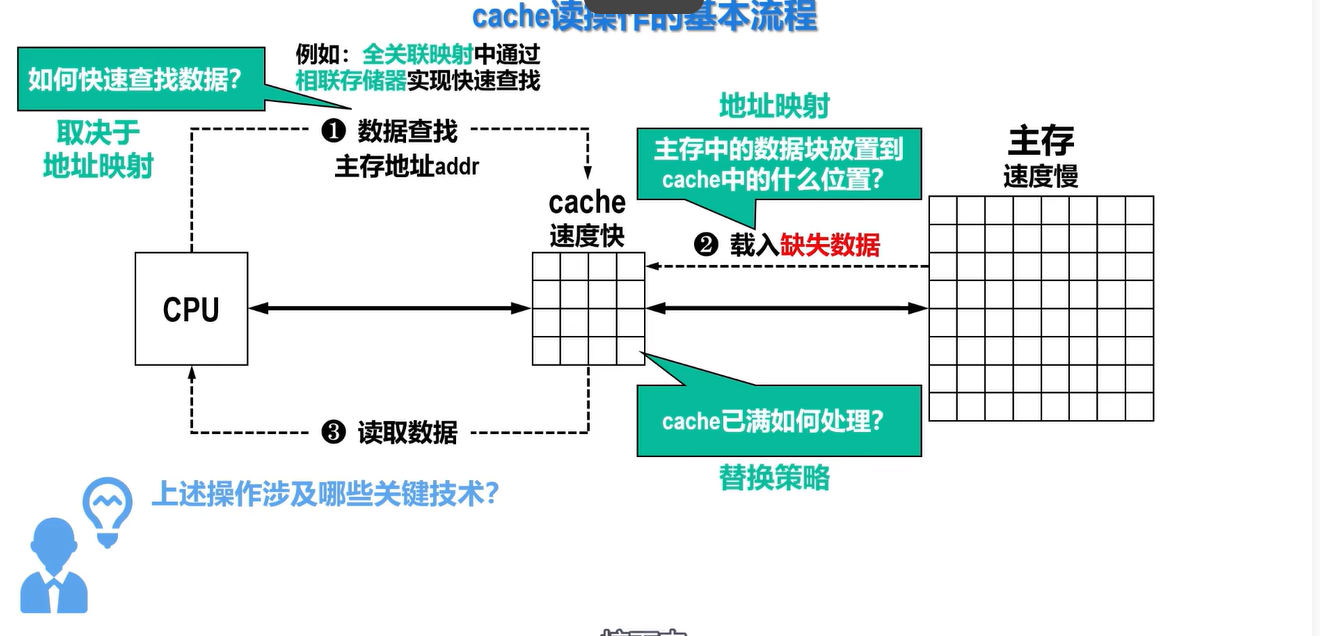
CPU发出主存地址
读操作命中访问时间最短
构建Cache时,应尽可能提高命中率,以提升读操作性能
- 通过较好的替换策略,将经常访问的热数据保留在Cache中,将不经常访问的冷数据淘汰,来充分利用时间局部性,以提高命中率
- 数据缺失时,会将缺失数据所在的数据块中其他数据一起载入,这种预读策略可充分利用空间局部性来提高顺序访问的命中率
Cache写操作
对Cache块内写入的信息,必须与被映射的主存块内的信息完全一致
如何使Cache与主存的内容保持一致:
- 写直达法
- 写操作时数据既写入 Cache 又写入主存
- 写操作的时间是访问主存的时间
- 随时保证主存与 Cache 数据一致,但增加了访存次数,降低了 CPU 效率
- 写回法
- 写操作时数据只写入 Cache 而不写入主存
- 当Cache数据被替换出去才写回主存
- 写操作的时间是访问 Cache的时间
- 读操作 Cache 失效发生数据替换时,被替换的块需写回主存,增加了 Cache 的复杂性
数据命中:
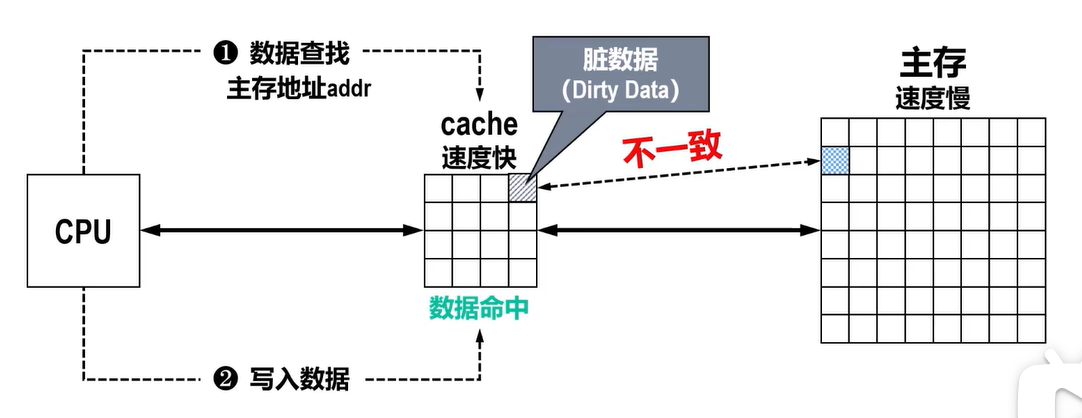
若使用写回(write-back)策略:仅写入Cache就结束,此时写入操作结束,这种方式响应速度最快,但会产生不一致性
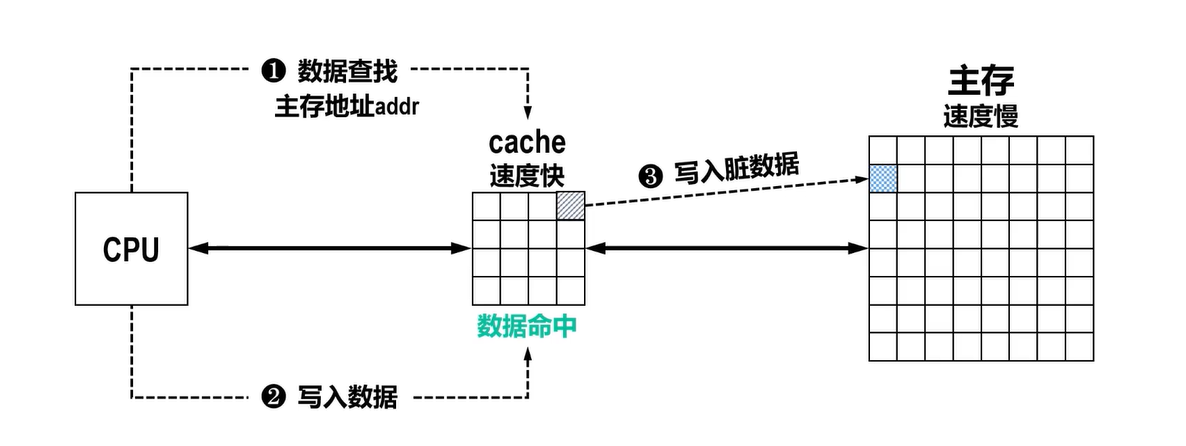
写直达法(write-through):Cache和主存都要写,一写到底此时还要将脏数据写入慢速的主存才能结束,这种方式响应速度较慢,但是没有脏数据产生数据缺失:
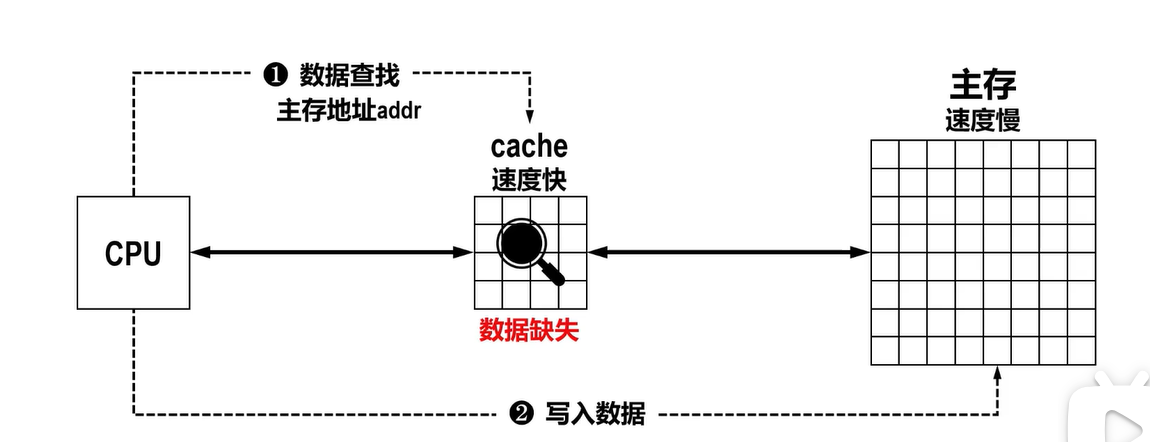
非写分配:将数据写入慢速主存就返回,不用为写入数据分配慢速Cache块
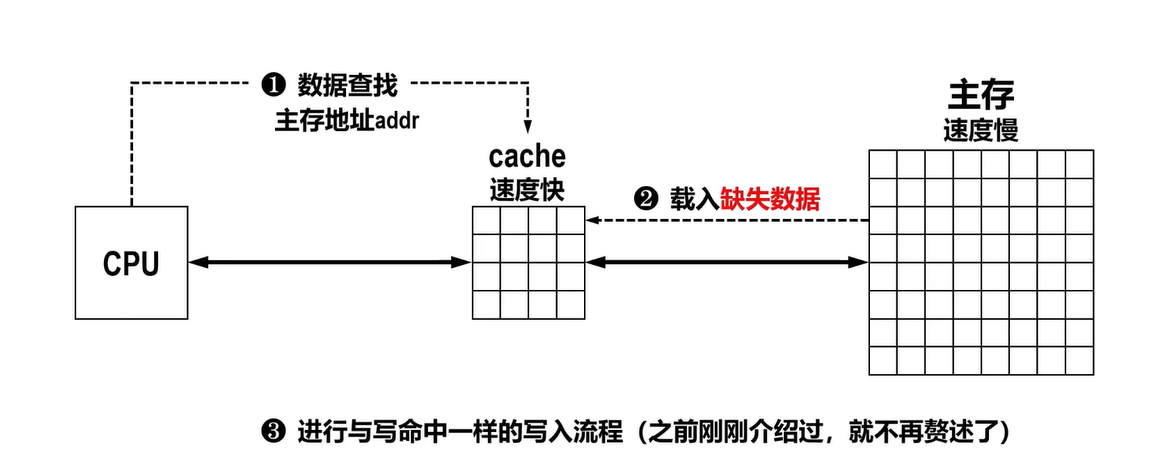
写分配策略:首先将缺失数据所在的主存数据块载入Cache中,执行与写命中时的写入流程
summary:
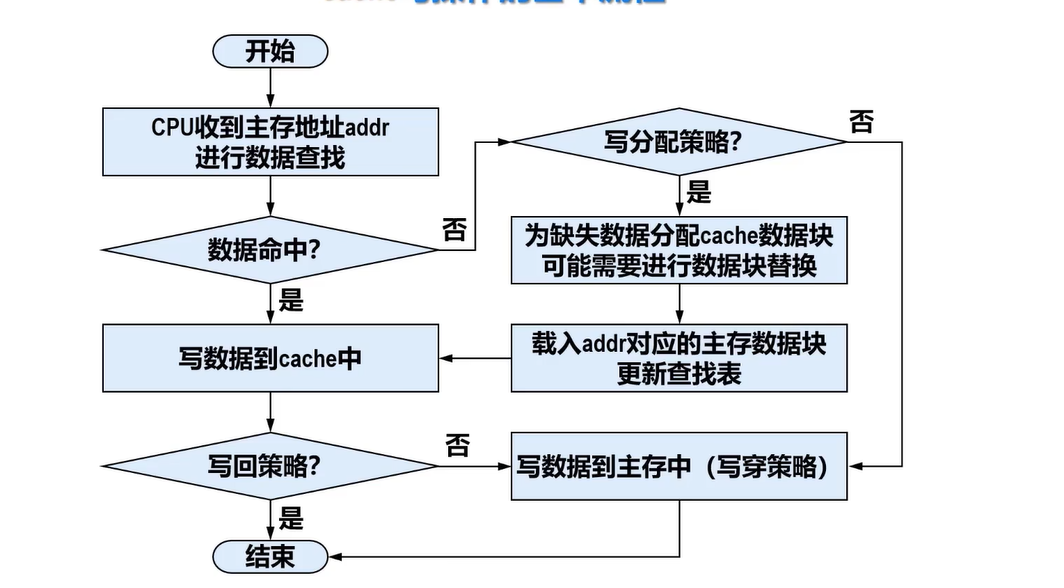
采用写回策略时,将数据写入Cache即可返回,写响应时间最短
- 对于突发的小数据量写入,Cache能明显提高写入性能高
- 然而,由于Cache容量很小,当Cache写满数据后,需要将Cache中的脏数据淘汰,这需要先将脏数据迁移到主存,从主存载入新数据块到Cache后才能向Cache写入新数据,该过程的写性能比没有采用Cache的主存还要慢
Cache-主存地址映射
区分Cache与主存的数据块对应关系
总览
取自王道课程
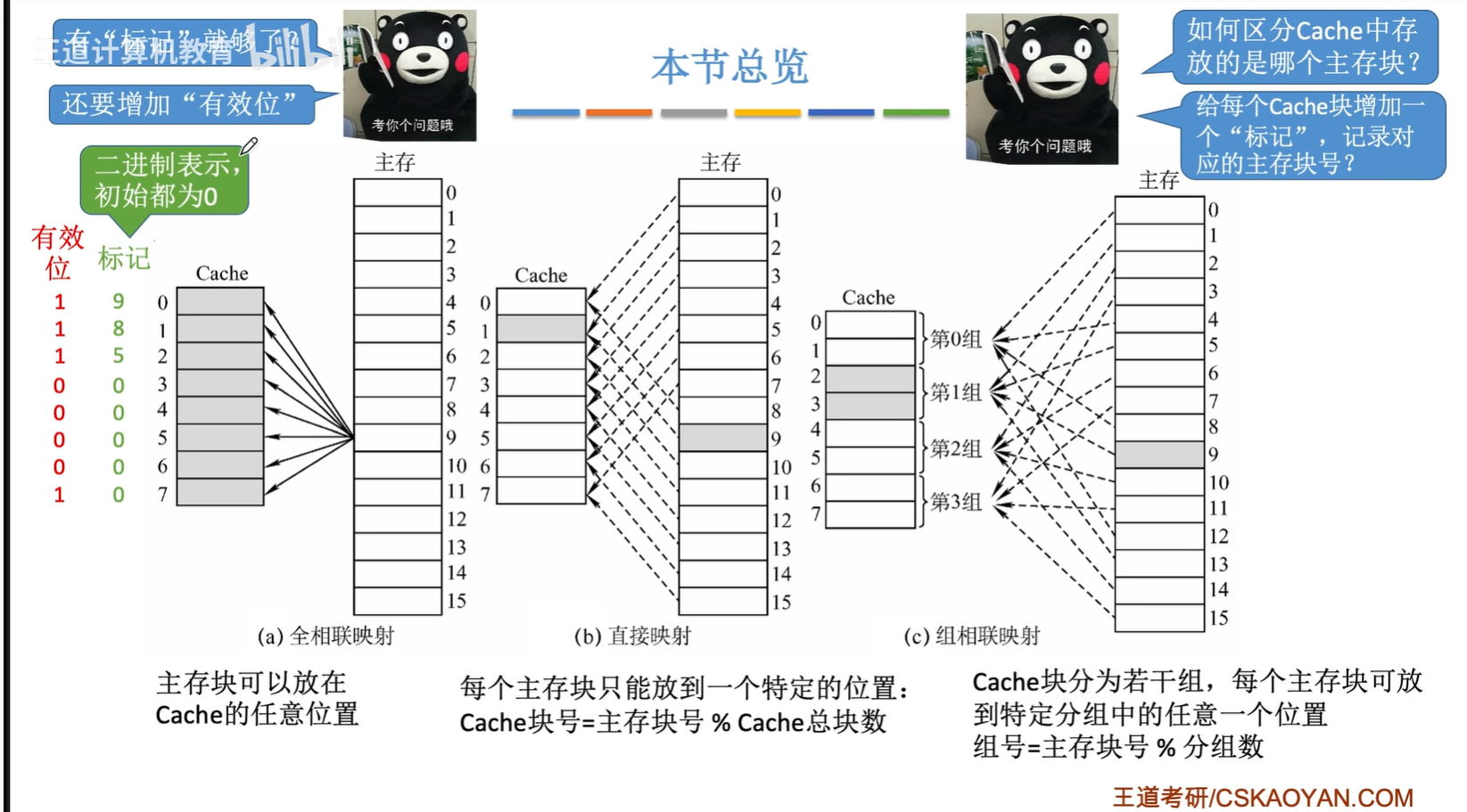
直接:某一主存块只能固定映射到某一缓存块
全相联:某一主存块能映射到任一缓存块
组相联:某一主存块能映射到某一缓存组中的任一块
一些基本概念
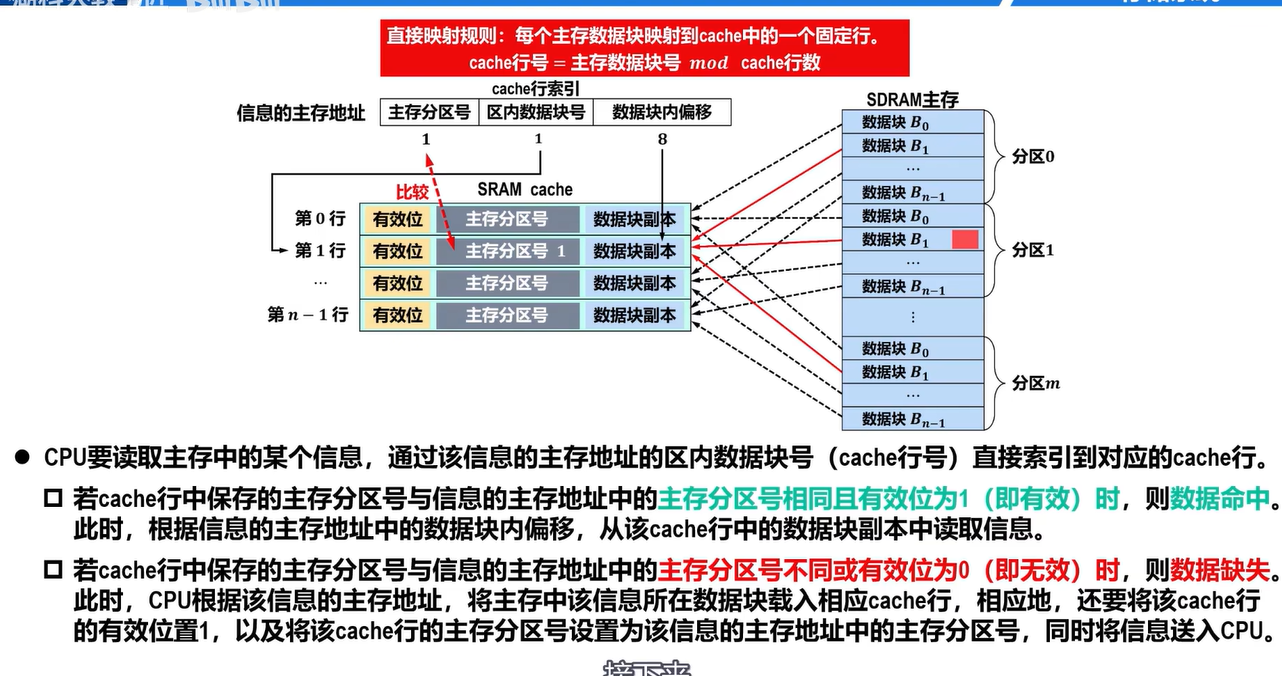
地址映射:由主存映射到Cache地址
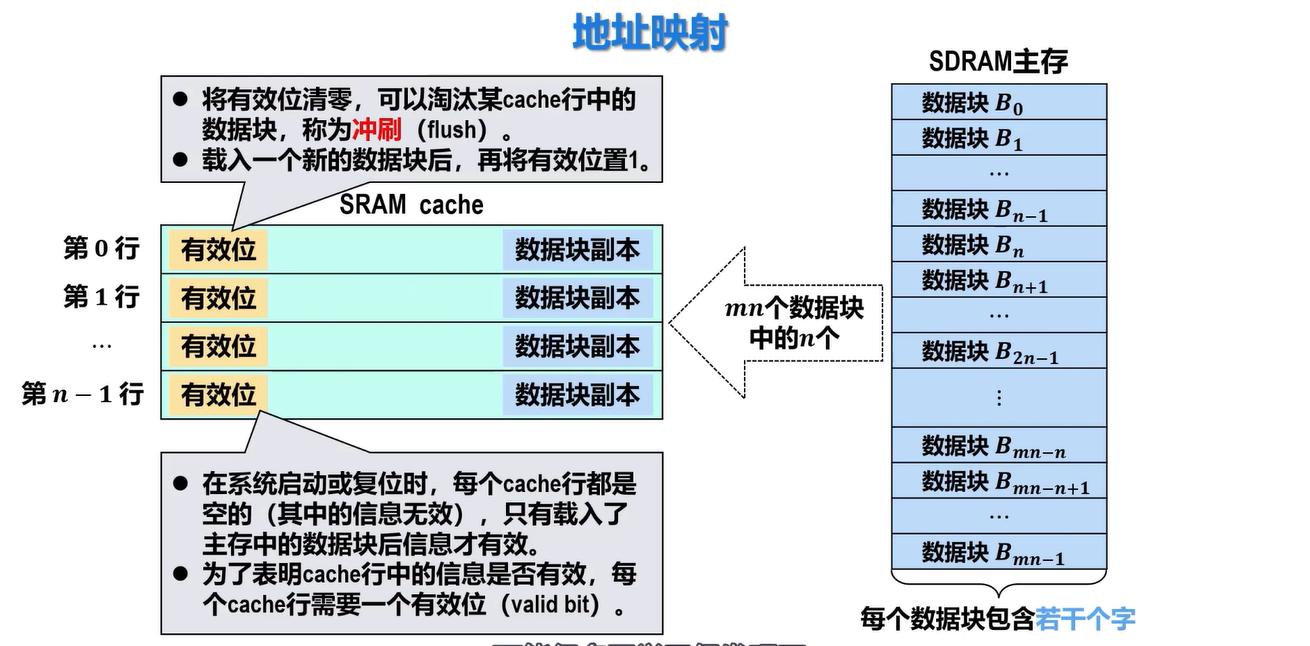
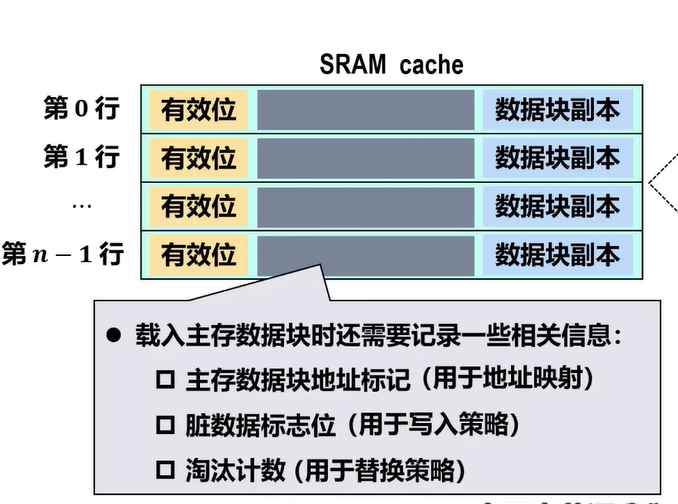
当某个主存数据块载入Cache行,它们之间应该采用某种映射规则,这样CPU要访问主存中的某个信息时,可依据映射规则到Cache对应行中查找信息,而不用在整个Cache中进行查找
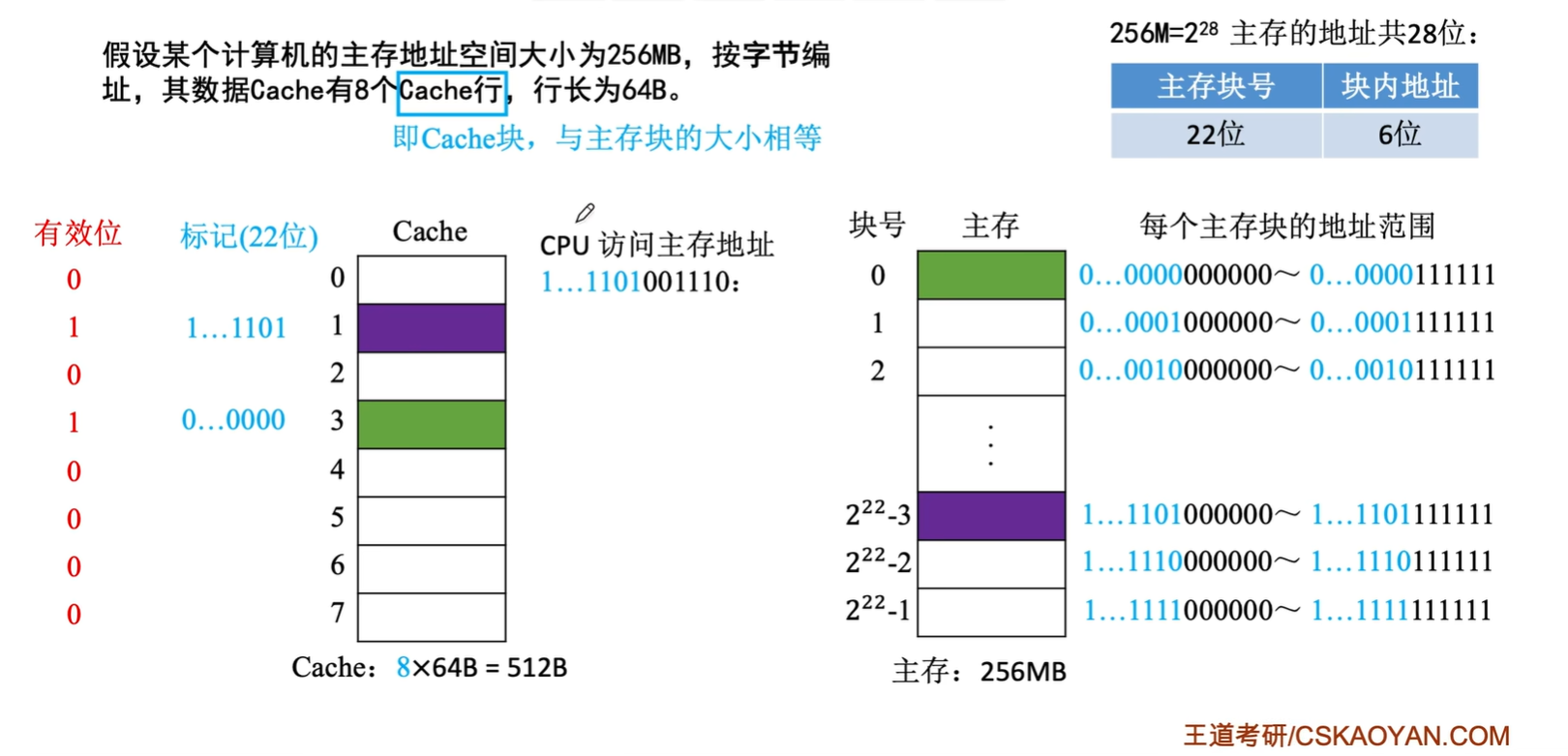
直接映射
原理
直接映射规则:每个主存数据块映射到Cache中的一个固定位置
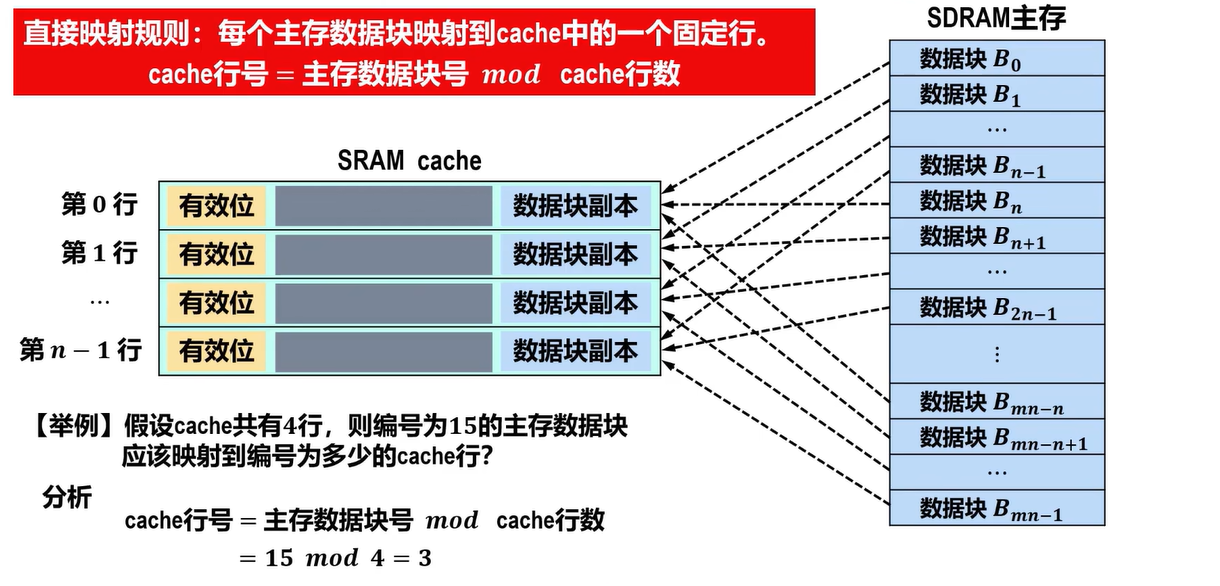
Cache块号=主存数据块号 mod Cache块数
由于该式中的各个量都是非负整数,可将模运算简单看作是求余运算
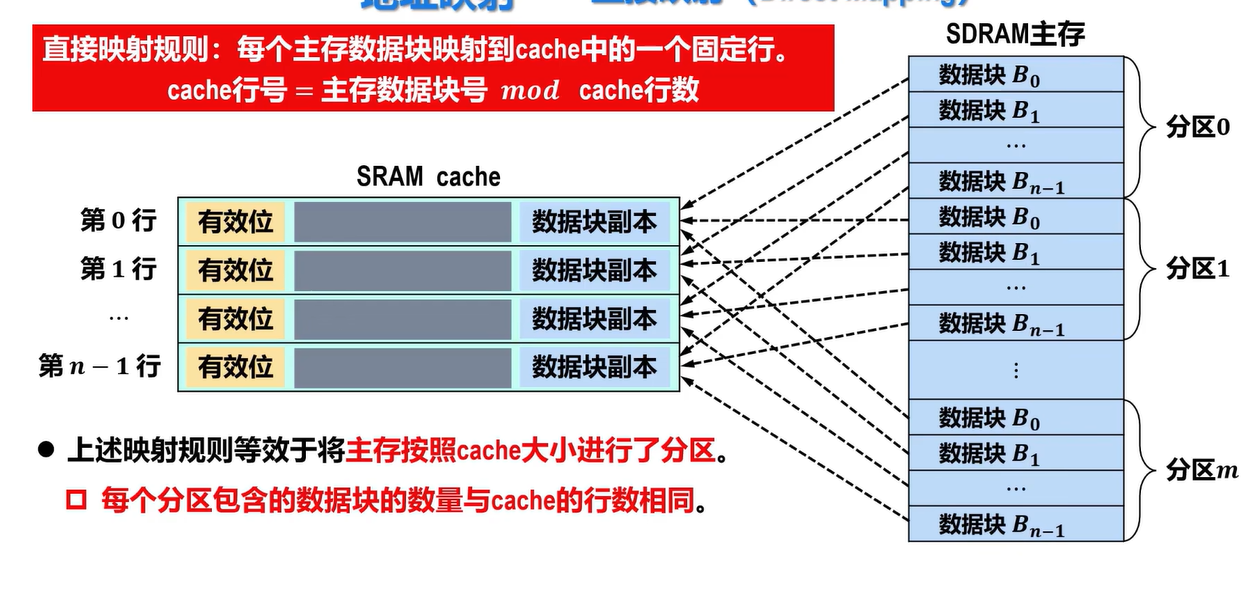
- 直接映射等效于将主存按照Cache大小进行了分区
- 每个分区包含的数据块的数量与Cache的块数相同
- 没有必要对主存中的全部数据块进行统一编号,而是对每个分区中的第一个数据块编号为0,后续每个数据块的编号依次加1,直到该分区的数据块全部编号完成
- 主存块号末尾n位直接反映在Cache中的位置,将主存块号的其余位作为标记即可
如何描述主存中某个信息的具体位置
主存分区号+区内数据块号+数据块内偏移
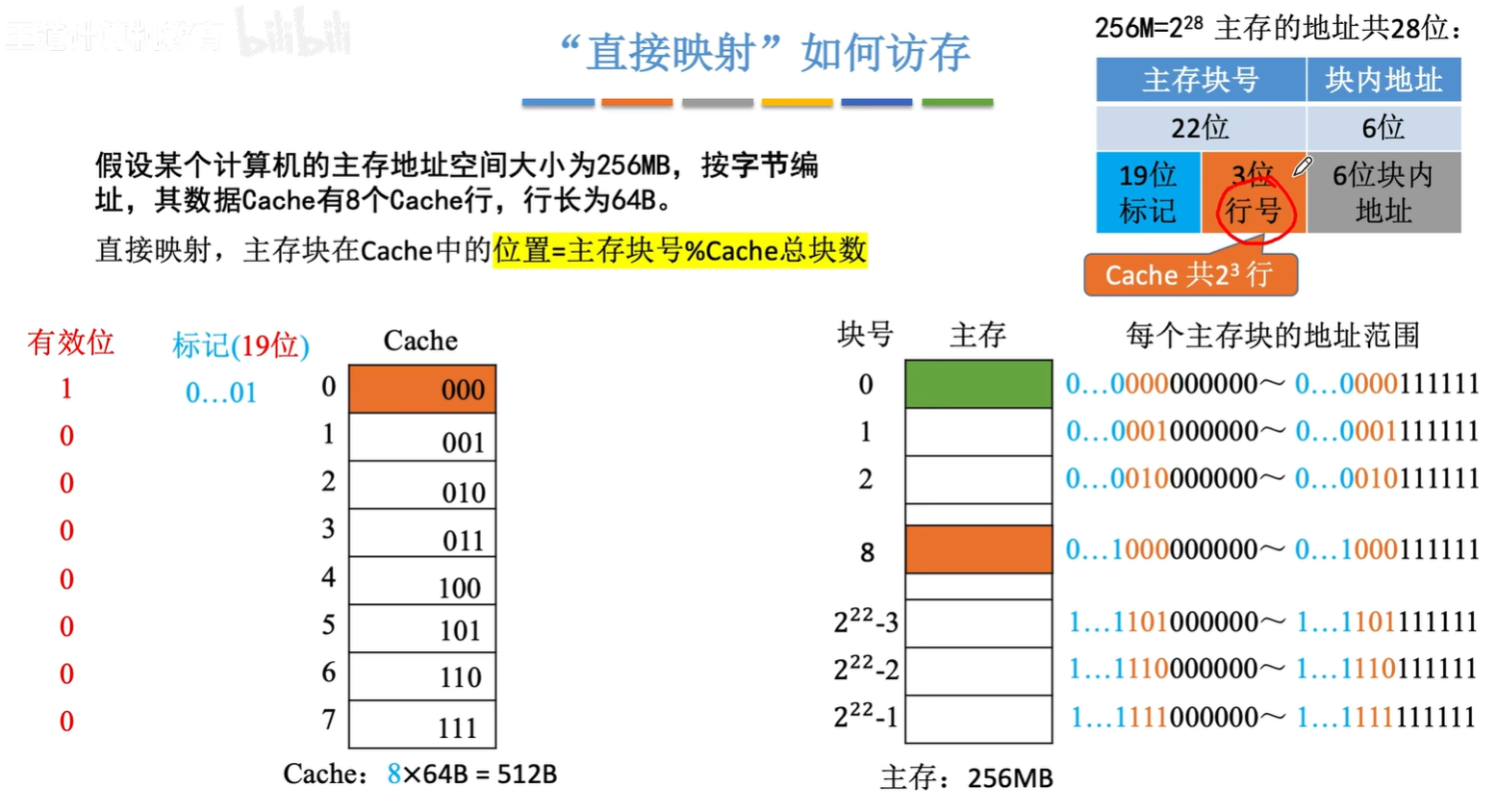
- 根据主存块号的后n位确定Cache行($2^n=\text{缓存块数}$)
- 若主存块号的前面(主存块号-n)位与Cache标记匹配,且有效位=1,则Cache命中
- 若未命中或有效位=0,正常访存
- 从主存读入新的字块来替代旧的字块,同时将信息送往CPU,修改Cache标记,如果原来有效位=0,还需置1
通过区内数据块号可精准定位出该数据块所映射到Cache中的固定行的行号,因此也成为Cache行索引
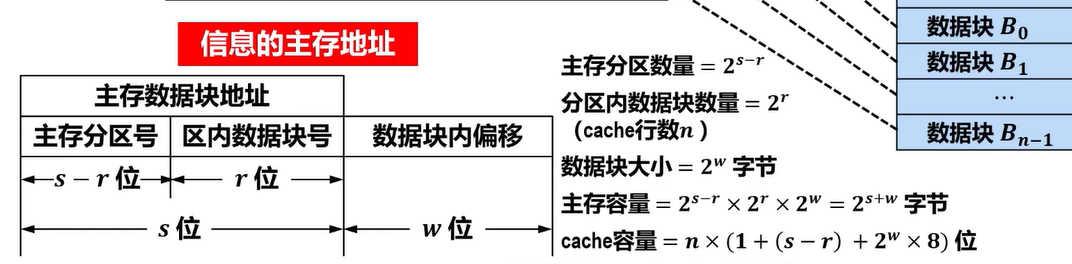

主存地址高m位被分成两部分
- 低c位指Cache的字块地址
- 高t位指主存字块标记
- 被记录在建立了对应关系的缓存块的标记位上
需要根据待访问信息的主存地址,将主存中该信息所在的数据块载入相应的Cache行,还需要将有效位置1以及将该Cache行的主存分区号设置为该信息的主存地址中的主存分区号
硬件逻辑实现
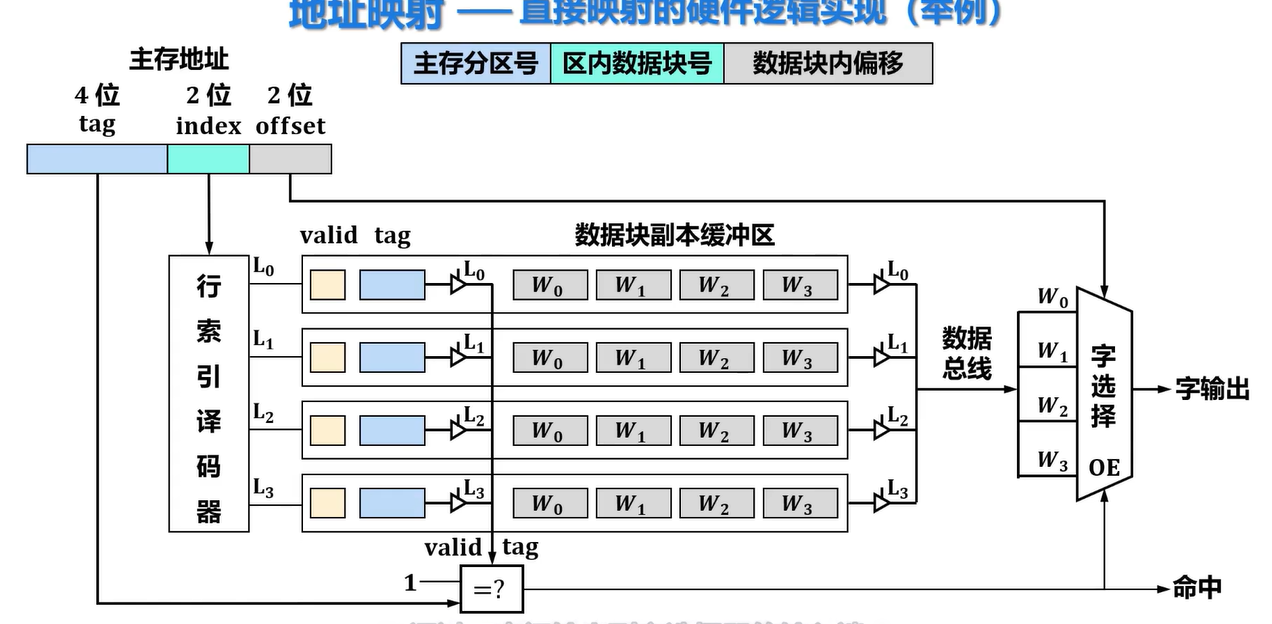
区内数据块号(Cache行索引)作为译码器的输入端输出相应的Cache行选通信号,该信号还连接所选中Cache行相关的两个三态门各自的控制端
被选通Cache行相关的第一列三态门被控制打开输出,因此该Cache行中的有效位和标记tag会通过三态门输出到比较器
被选通Cache行相关的第二列三态门被控制打开输出,因此该Cache行中数据块副本缓冲区的四个字通过三态门输出到字选择器的输入端,若比较器判断被选通三态门有效位为1,并且tag值与主存地址中标记tag值相同,则比较器输出命中信号,使能字选择器,字选择器根据主存地址中偏移offset值选择自身输入端中相应的输入端进行输出。
运行过程:
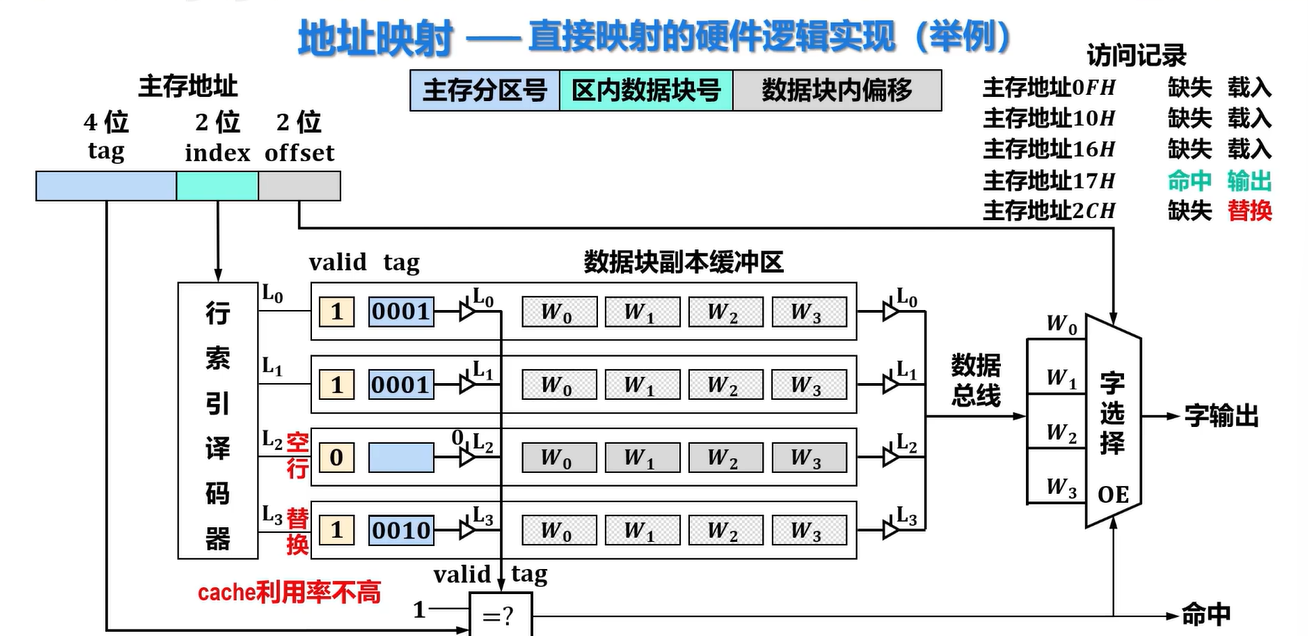
特点
- 每个主存数据块映射到Cache中的一个固定行,实现简单,不够灵活
- Cache利用率低
- Cache命中率低
- Cache冲突率高(未满也可能出现数据块替换)
- 对于快速查找的硬件实现,成本较低,适合于大容量Cache使用
- 替换算法较为简单,如果访问不命中则直接替换相应Cache即可,但若该Cache存在脏数据,则需要将脏数据写入二级存储器以保证数据一致性
全相联映射
映射规则
映射规则:允许主存中每一字块映射到Cache中的任何一块位置上
- 新的主存数据块可以载入到Cache中的任何一个空行
- 只有Cache满时,才需要进行数据块替换

如何描述主存中某个信息的位置:
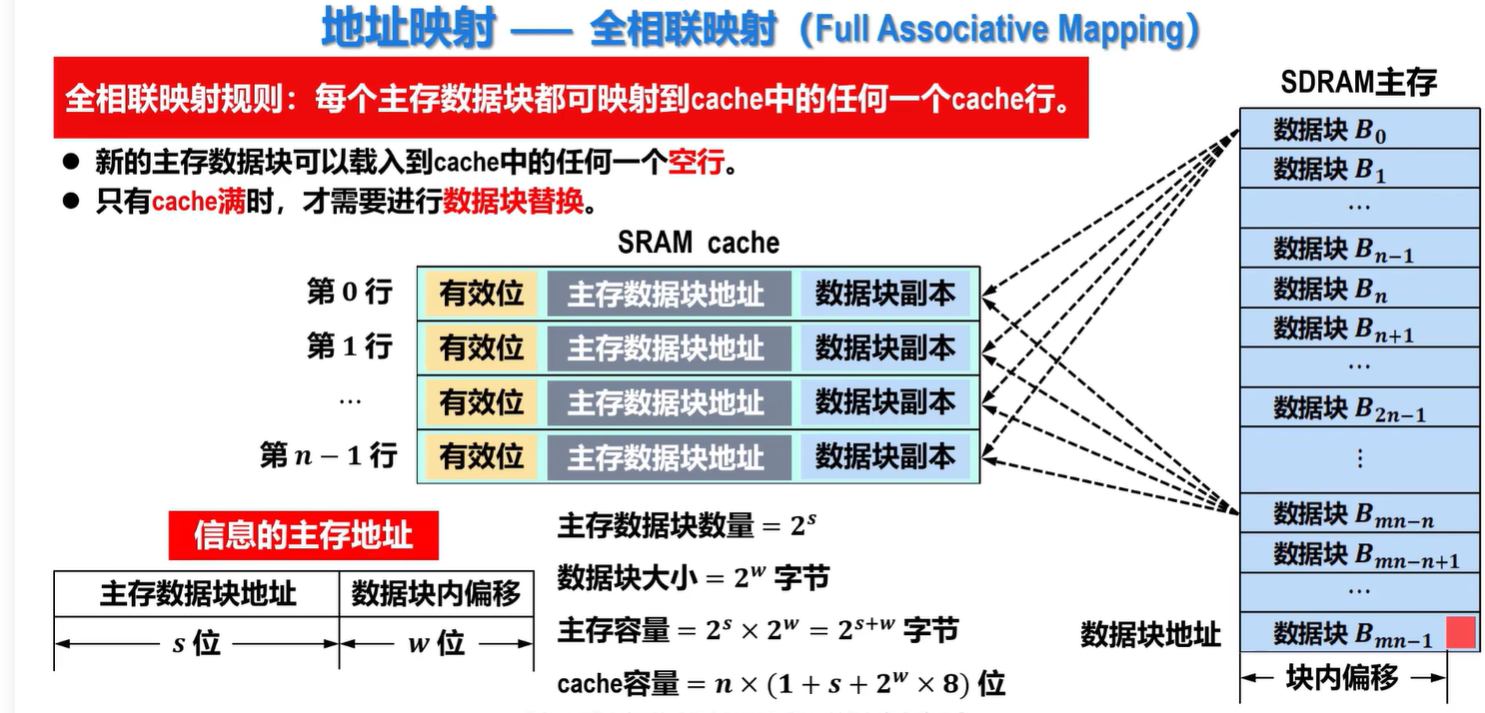
如何根据信息的主存地址在Cache中快速查找:
- 直接将主存数据块地址与所有Cache行中的主存数据块地址【标记】进行并发比较
- 若标记匹配且有效位为1,则Cache命中
- 读操作,则输出相应Cache行数据块副本中块内偏移处的信息
- 写操作,则写入数据,同时将脏数据标志位置1
- 若未命中或有效位=0,则正常访问主存 特点:映射方式灵活,但结构复杂,成本高
组相联映射
对直接映射和全相联映射的一种折中,主存块可放到特定分组
组相联映射,所属分组=主存块号%分组数
$i=j\quad mod\quad Q$
i:缓存的块号
j:主存的块号
Q:分组数
主存块号末尾n位直接反映在Cache中的组数,将主存块号的其余位作为标记即可
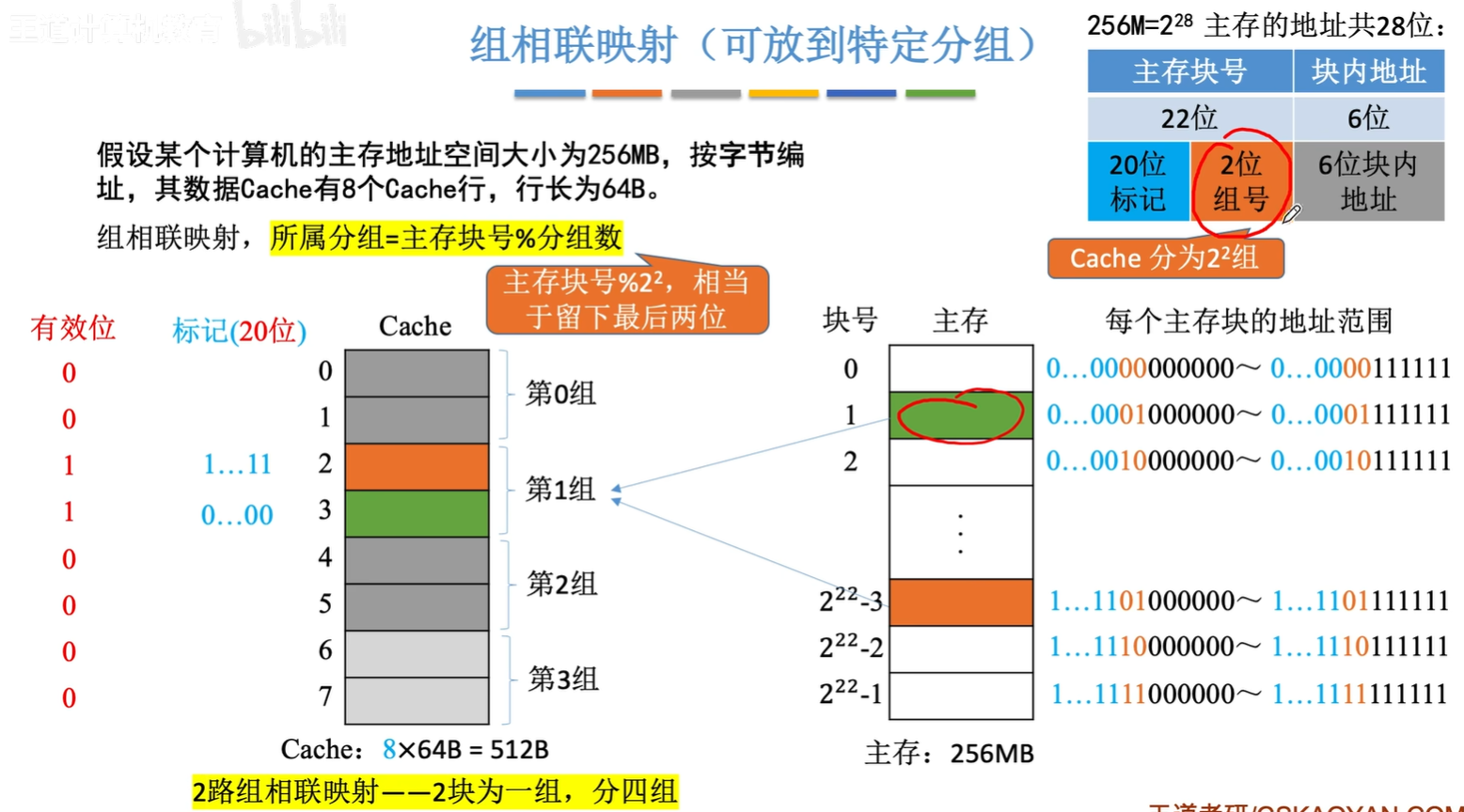

如何进行访存:
- 根据主存块号的后n位确定所属的分组号
- 若主存块号的其余位与分组内的某个标记匹配且有效位=1,则Cache命中
- 若未命中或有效位=0,则正常访问主存
组相联映射方式的性能与复杂性介于直接映射与全相联映射两种方式之间:
当 r = 0(即每组仅一块)时,它就是直接映射方式;
当 r = c(即总共仅一组)时,就是全相联映射方式。
在实际 Cache 中常用直接映射 (r = 0),两路组相联映射 (r= 1) 和 4 路组相联映射 (r = 2)
替换策略
Cache很小,主存很大,Cache满后的处理策略
- 先进先出算法
- 近期最少使用算法
- 随机法


