
标签
07 指令系统
日期
Place
创建时间
Jan 8, 2026 01:51 PM
指令系统概述
计算机是按照程序员事先编制好的程序进行工作的
程序会被翻译(编译、汇编或解释)成一系列相应的指令,这些指令告诉计算机如何执行特定的任务
- 指令是计算机能够理解和执行的基本命令,指示执行某种操作的命令,是计算机运行的最小功能单位
- 每条指令必须显式或隐式提供以下信息
- 执行的操作
- 操作数的来源
- 操作结果的存放处
- 下一条指令的地址(一般不需要在指令中显式给出,而是隐含在程序计数器pc中)
- 指令按顺序执行时,pc的值会自动加上指令长度,来得到下一条指令的地址
- 当遇到转移指令而不按顺序执行时,需要由指令给出转移到目的地址
- 机器指令是计算机硬件与软件的界面,也是用户操作和使用计算机硬件的接口 一台计算机中所有指令的集合称为该计算机的指令集,也成为指令系统
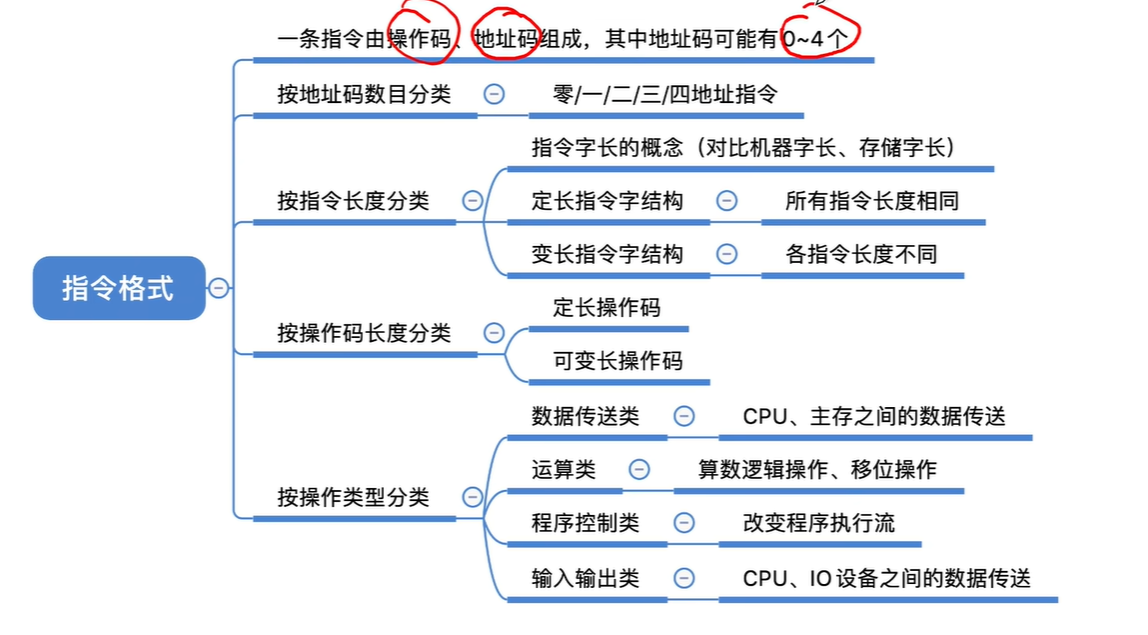
指令的一般格式和指令字长
指令的一般格式
操作码字段OP+地址码字段A
- 操作码反映机器做什么操作
- 地址码指明相应的操作数,可以包含多个操作数---操作对象
- 寻址方式决定了操作数的存放位置和访问方式
地址码
根据地址码数目不同分类
零地址指令
只需给出操作码,无需地址码
case:
- 不需要操作数,如停机指令、关中断、内存栅栏、空操作等指令
- 堆栈计算机(不是不需要,操作数固定隐含在特定位置),两个操作数隐含存放在栈顶和次栈顶,计算结果压回栈顶
一地址指令
case:
- 只需要单操作数
- 指令含义OP(A1)->A1
- 完成一条指令需要3次访存,取指-读A1-写A1
A1指某个主存地址,(A1)表示A1所指向的地址中的内容
- 需要两个操作数,但其中一个操作数隐含在某个寄存器(如隐含在ACC)
- 指令含义:(ACC)OP(A1)->ACC
- 完成一条指令需要两次访存:取指->读A1
ACC 是 “累加器(Accumulator)” 的缩写
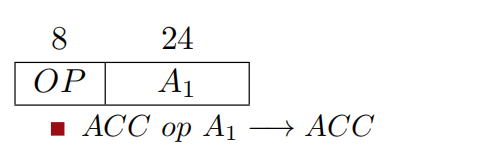
二地址指令
case:常用于需要两个操作数的算术运算、逻辑运算相关指令
A+=B

指令含义:(A1)OP(A2)->A1
完成一条指令需要访存4次,取值-读A1-读A2-写A1(3次访操作数,一次访下条指令)
三地址指令

case:常用于需要两个操作数的算术运算、逻辑运算相关指令
指令含义:(A1)OP(A2)->A3
完成一条指令需要访存4次,取值-读AI-读A2-写A3(3次访操作数,1次访下条指令)
四地址指令

指令含义:(A1)OP(A2)->A3
A4:下一条指令地址
(
下一条要执行的指令本身所在的位置编号
)
完成一条指令需要访存4次,取值-读AI-读A2-写A3
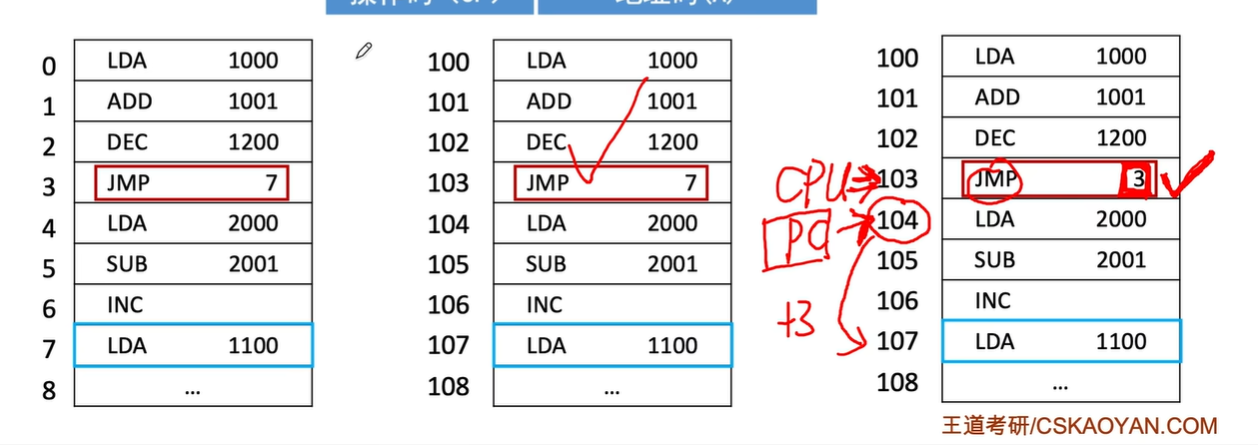
正常情况:取指令后PC(程序计数器)+1,指向下一条指令
专门用来存储 “下一条要执行的指令的地址”,是 CPU “按顺序执行指令” 的关键部件
四地址指令:执行指令后,将PC的值修改为A4所指向地址
地址码的位数
n位地址码的直接寻址范围=2^n
若指令总长度固定不变,则地址码数量越多,寻址能力越差(每个地址码的位数越短)
补充:
当用一些硬件资源(PC、ACC)代替指令字中的地址码字段后
- 可扩大指令的寻址范围
- 可缩短指令字长
- 可减少访存次数
当指令的地址字段为寄存器时
寄存器是 CPU 内部的高速存储部件
三地址 OP R1, R2, R3
二地址 OP R1, R2
一地址 OP R1
- 可缩短指令字长
- 指令执行阶段不访存
操作码
指令可按操作码长度进行分类: 定长操作码 可变长操作码
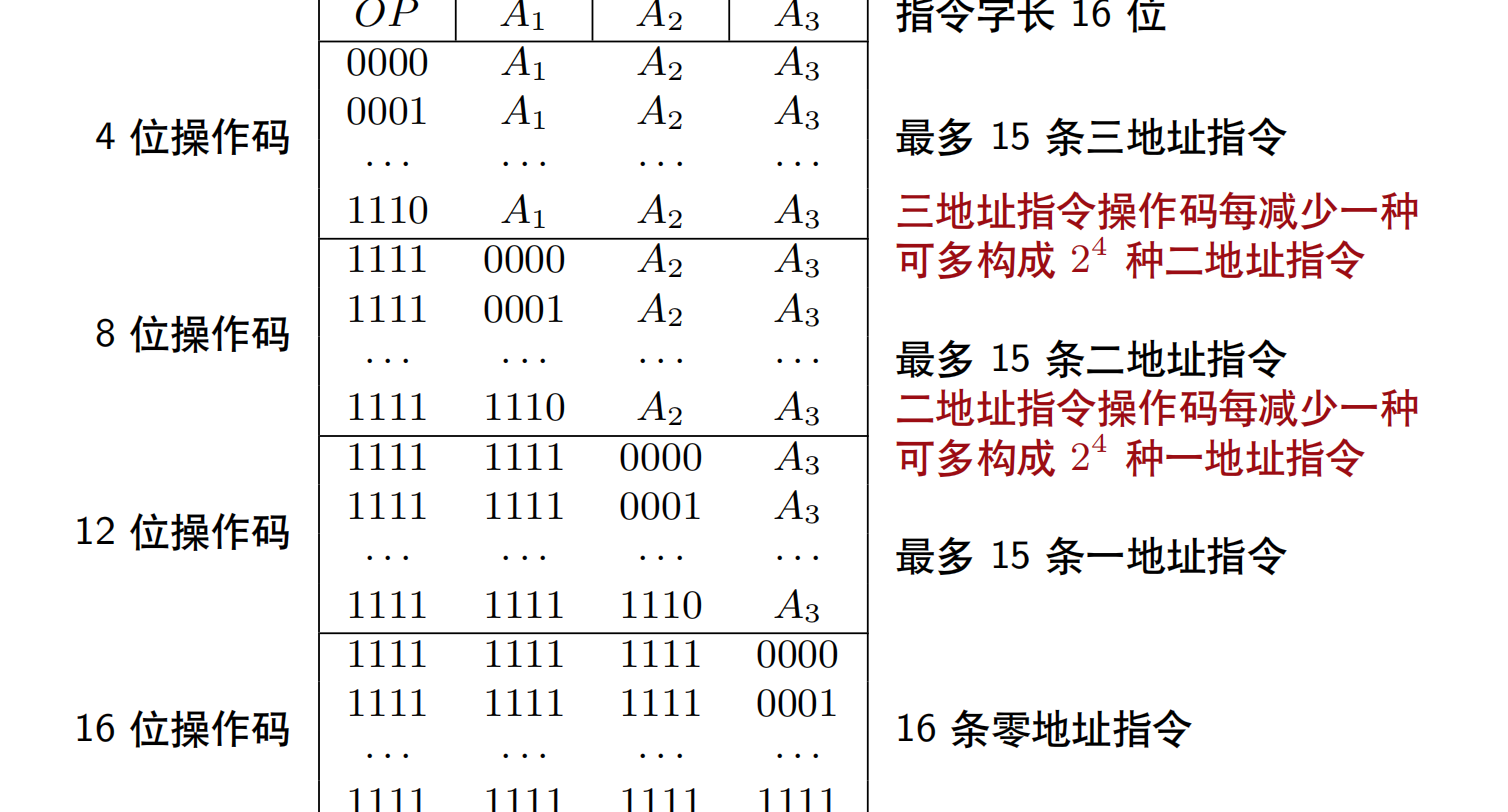
扩展操作码技术
定长指令字结构+可变长操作码 不同地址数的指令使用不同长度操作码 操作码的位数随地址数的减少而增加


通常情况下,
对使用频率较高的指令分配较短的操作码
,对使用频率较低的指令分配较长的操作码,从而尽可能减少指令译码和分析时间
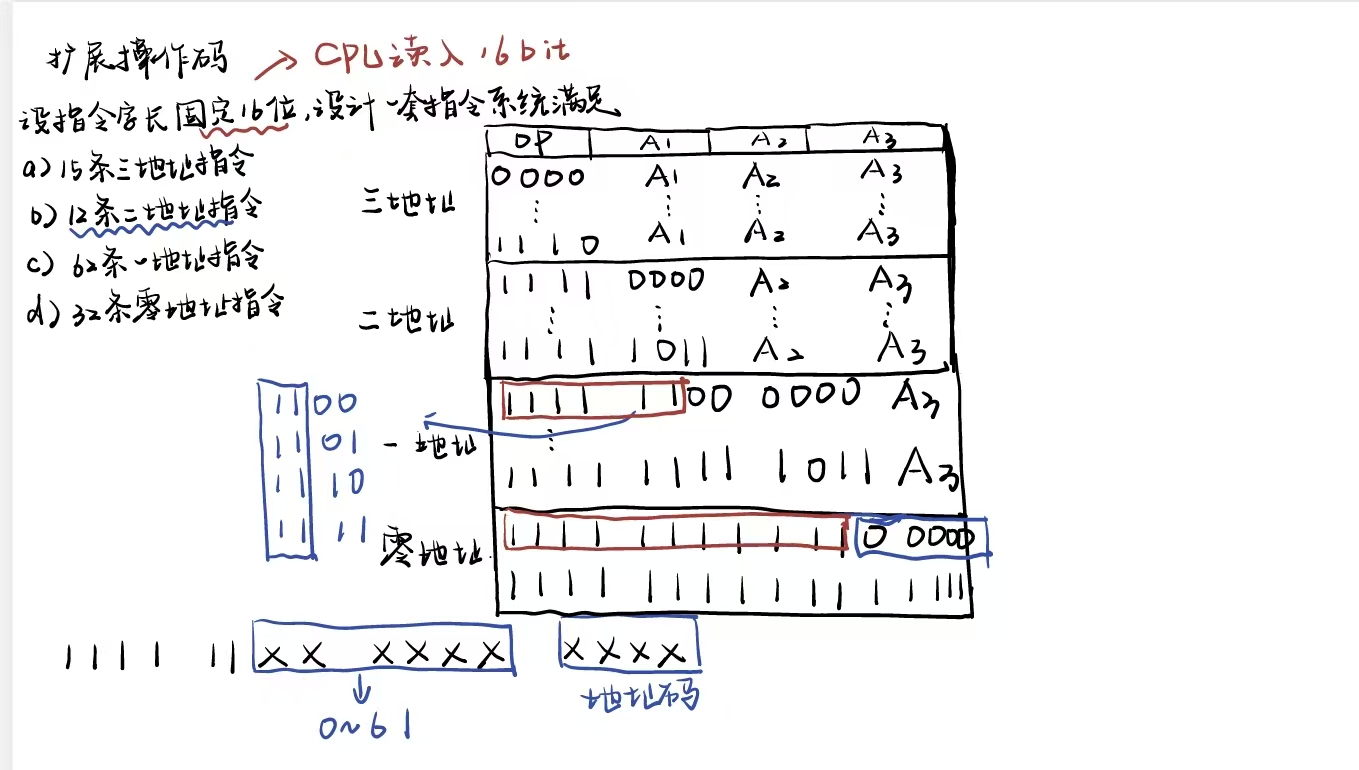
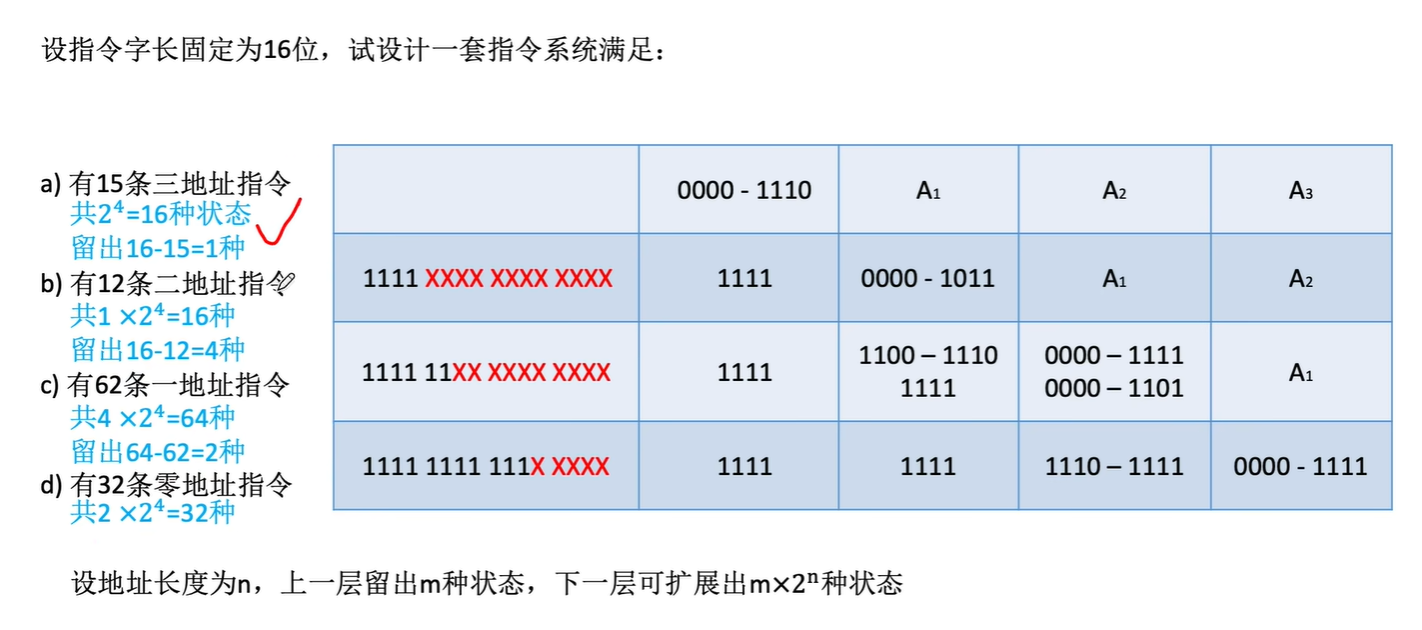
设地址长度为n位,上一层留出m种状态,下一层可多扩展出mx2^n种状态
分类方式
- 根据地址码数目不同分类
- 根据指令长度进行分类
- 根据操作码的长度不同分类
- 根据操作类型进行分类
- 数据传送类:进行主存与CPU之间的数据传送
- LOAD:把存储器中的数据放到寄存器中
- STORE:把寄存器中的数据放到存储器中
- 运算类
- 算术逻辑操作
- 移位操作
- 程序控制类:改变程序执行的顺序
- 转移操作---PC值(指明下条指令存放地址)改变
- 无条件转移JMP
- 输入输出类:进行CPU和I/O设备之间数据传送
- CPU寄存器与IO端口之间的数据传送

指令字长
定义:构成指令的二进制位数,指令总长度(可能会变)
指令字长:一条指令总长度 机器字长:CPU进行一次整数运算所能处理的二进制数据的位数)---通常和ALU相关 存储字长:一个存储单元中二进制代码位数---通常和MDR位数相同
半字长指令、单字长指令、双字长指令---指令字长是机器字长的多少倍

根据指令长度不同分类
- 定长指令系统
- 指令长度固定,指令系统所有指令的长度都相等
- 结构简单,有利于指令顺序寻址、取指和译码
- 指令字长=存储字长xN
- 变长指令系统
- 指令长度可变,指令系统各种指令的长度不等
- 结构灵活,给取值和译码带来不便,取值过程可能涉及多次访存操作
- 指令字长=nB(按字节倍数变化) 由于存储器的基本编址单位为字节,而指令是存储在存储器中的,因此无论是定长指令系统还是变长指令系统,指令字长都是字节的整数倍

影响因素
- 操作码的长度
- 操作数地址长度
- 操作数地址的个数
操作数的类型和操作种类
操作数类型
- 地址 无符号整数
- 数字 定点数、浮点数、十进制数
- 字符 ASCII
- 逻辑数 逻辑运算
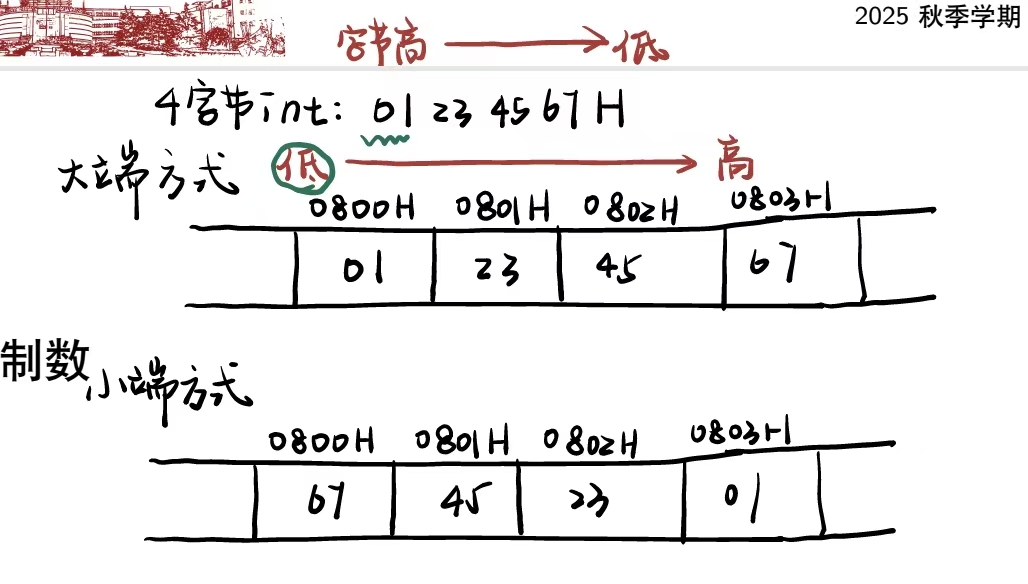
数据在存储器中的存储方式
- 小端序:字地址为低字节地址
- 数据的低位字节存在内存的低地址,高位字节存在内存的高地址
- 大端序:字地址为高字节地址
- 数据的高位字节存在内存的低地址,低位字节存在内存的高地址
操作类型
- 数据传送

- 算术逻辑操作
- 移位操作
- 算术移位
- 逻辑移位
- 循环移位(带进位、不带进位)
- 转移
- 无条件转移JMP
- 条件转移
- 根据当前指令的执行结果来决定是否需要转移,若条件满足则转移;若条件不满足,则继续按顺序执行
- 结果为零转 (Z = 1) JZ
- 结果溢出转 (O = 1) JO
- 结果有进位转 (C = 1) JC
- 跳过一条指令 SKP
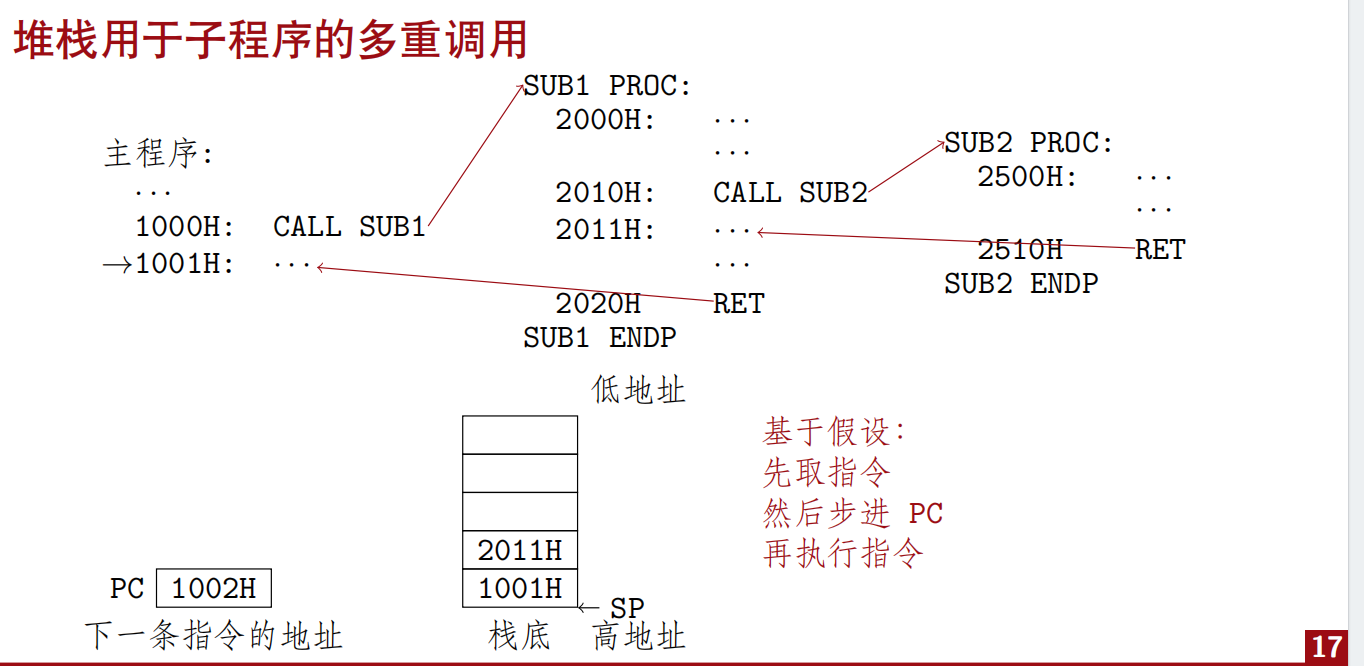
- 调用和返回
- CALL和RETURN
- 陷阱与陷阱指令
- 意外事故的中断(陷阱)
- 一般不提供给用户直接使用
- 在出现事故时,由CPU自动产生并执行(隐指令)
- 设置供用户使用的陷阱指令
- 提供给用户使用的陷阱指令,完成系统调用
- 输入输出
- 入:端口地址->CPU的寄存器
- 出:CPU的寄存器->端口地址
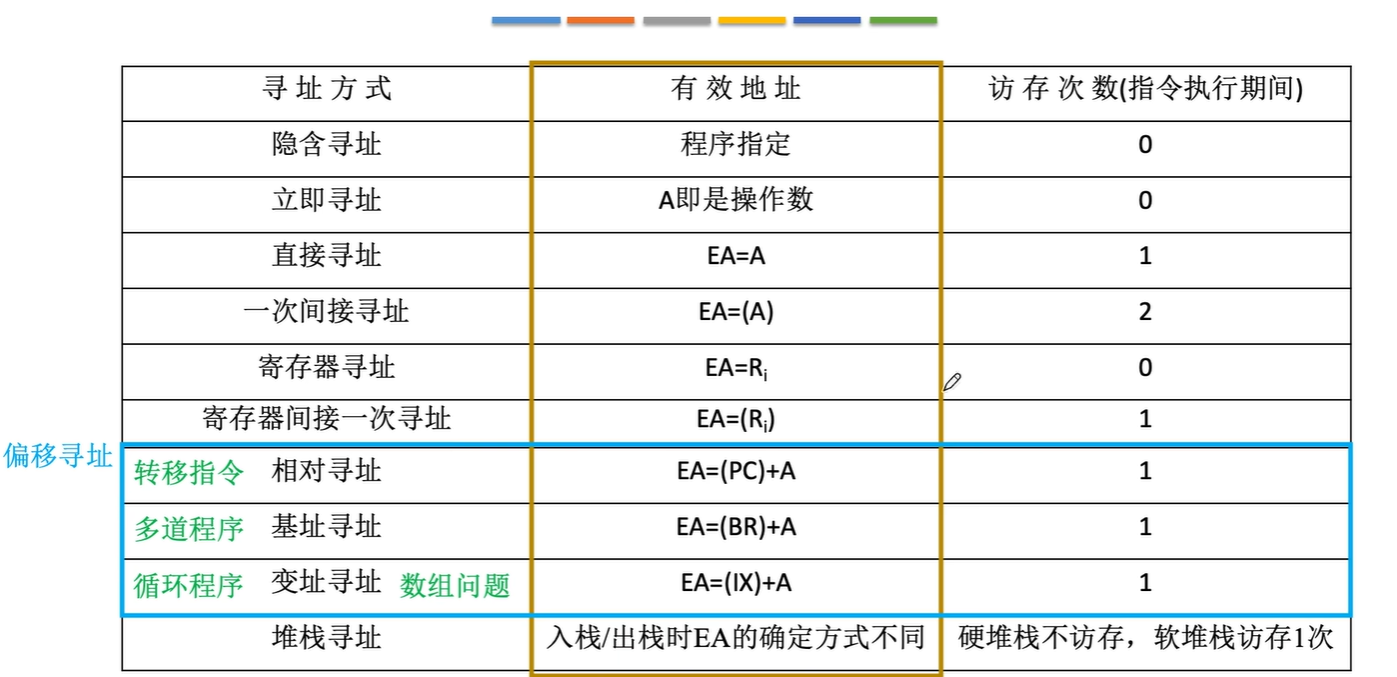
寻址方式🔆
确定本条指令的数据地址以及下一条将要执行的指令地址的方法 始终由程序计数器PC给出
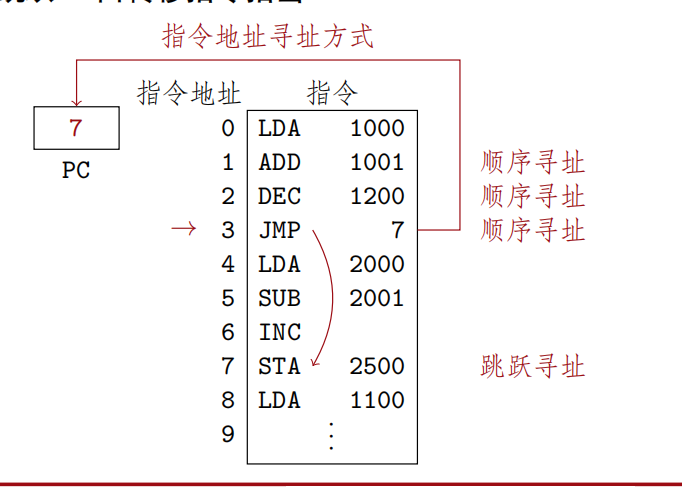
指令寻址
顺序寻址
程序计数器PC指明下一条指令的存放地址
顺序寻址:(PC)+1->PC
这里的1理解为1个指令字长,实际加的值会因为指令长度、编制方式而不同
按字编址
下一条指令的地址:(PC)+1->PC
按字节编址
下一条指令的地址:(PC)+当前指令字节数->PC
变长指令字系统+按字节编址:

跳跃寻址
由转移类指令指出
每一次取指令之后,
PC一定会自动+1
,指向下一条应该执行的指令
JMP:无条件转移,更改PC中的内容
数据寻址
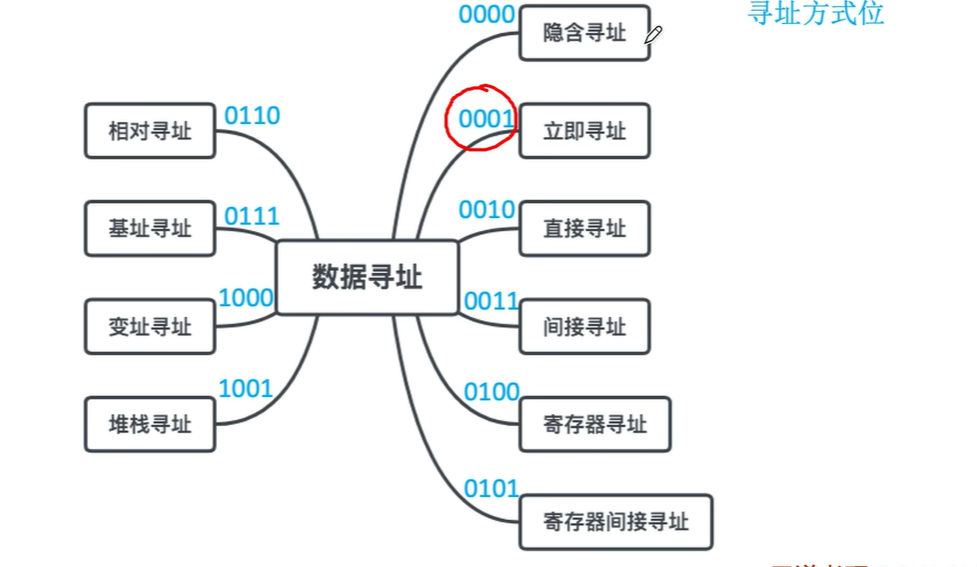
确定本条指令的地址码指明的真实地址 数据寻址方式种类较多,在指令字中必须设一字段来指明属于哪一种寻址方式
- 中:基于起始位置的偏移量
- 右:基于PC程序计数器往后偏移的位置

形式地址A:指令字的地址/指令的地址码字段
有效地址EA:操作数的真实地址,由寻址方式和形式地址共同决定
假设指令字长=机器字长=存储字长
直接寻址
指令字中的形式地址A就是操作数的真实地址EA
$$EA=A$$
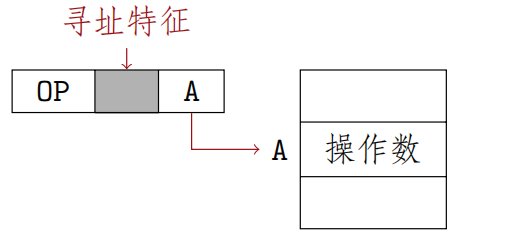
优点:寻找操作数比较简单,也不需要专门计算操作数的地址,
在指令执行阶段对主存只访问一次
,在指令执行阶段对主存仅访问一次
缺点:A的位数限制了操作数的寻址范围,必须修改A的值才能修改操作数的地址(操作数的地址不易修改)
间接寻址
指令字中的形式地址不直接指出操作数的地址,而是之处操作数有效地址所在的存储单元地址,有效地址是由形式地址间接提供的
$$EA=(A)$$
EA为A所指向的主存单元的数据
一次间接寻址
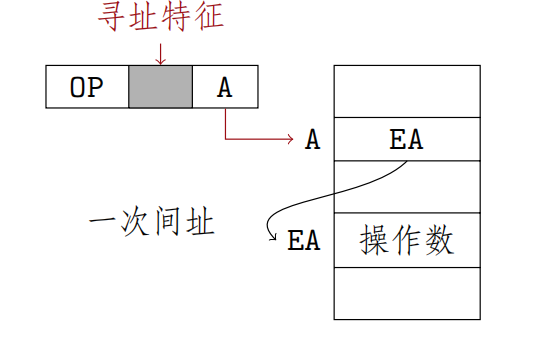
指令执行阶段进行2次访存二次间接寻址
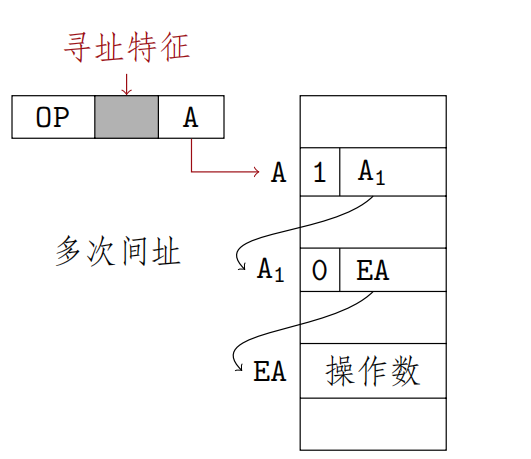
代表 “还要继续寻址”,
代表 “已经是最终地址”
优点:
- 可扩大寻址范围(有效地址EA的位数大于形式地址A的位数)
- 便于编制程序,用间接寻址可以方便地完成子程序的返回 缺点: 指令在执行阶段需要多次访问,致使指令执行时间延长
寄存器寻址
在指令字中,地址码字段直接指出了寄存器的编号,其操作数在由Ri所指的寄存器中
$$EA=R_i$$
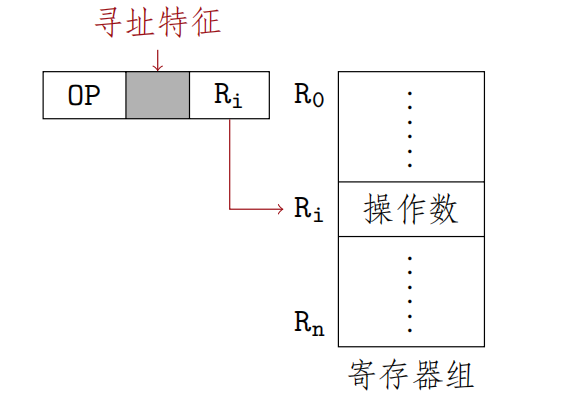
优点:
- 由于操作数不在主存中,寄存器寻址在指令执行阶段无须访存,减少了执行时间,执行速度块
- 地址字段只需指明寄存器编号(计算机中寄存器数有限),指令字较短,节省了存储空间 缺点: 寄存器价格昂贵,计算机中寄存器个数有限
寄存器间接寻址
Ri中的内容不是操作数,而是操作数所在的主存单元的地址号,有效地址:
$$EA=(R_i)$$
有效地址在寄存器中,操作数在存储器中,执行指令需访问一次内存
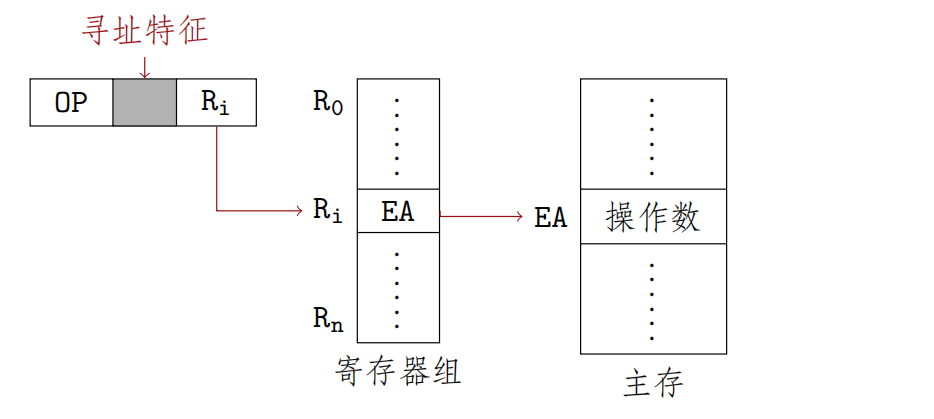
优点:
- 比一般间接寻址速度更快
- 有利于在指令字长有限的情况下,扩大寻址范围
隐含寻址
指令字中不明显给出操作数的地址,其操作数的地址隐含在操作码或某个寄存器中
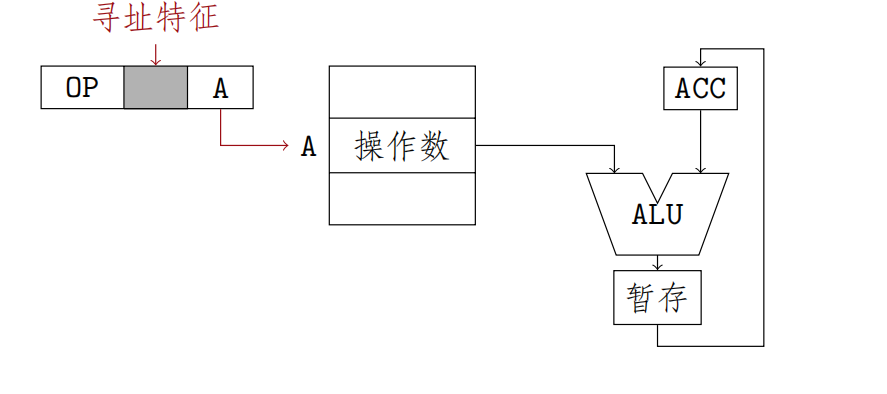
eg:一地址格式的加法指令只给出一个操作数的地址,另一个操作数隐含在累加器ACC中,这样累加器ACC就成了另一个数的地址
优点:
指令中少一个字段,有利于缩短指令字长
缺点:需要增加存储操作数/隐含地址的硬件
立即寻址
操作数本身设在指令字内
,形式地址A不是操作数的地址,而是
操作数本身
又称为立即数,一般采用
补码
表示
表示
立即寻址特征标记

优点:
指令执行阶段不访问主存,指令执行时间最短
缺点:
A的位数限制了立即数的取值范围

偏移寻址
以某个地址作为起点,形式地址视为“偏移量”

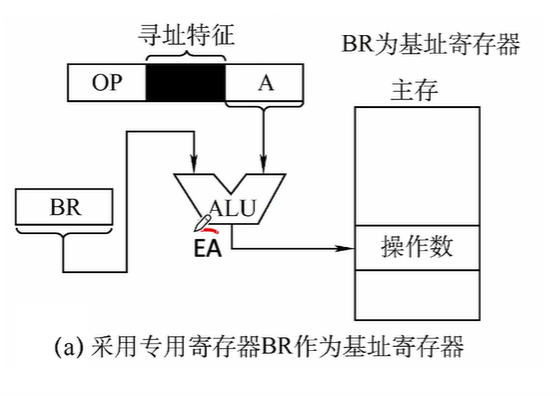
基址寻址
以程序的起始存放地址作为起点
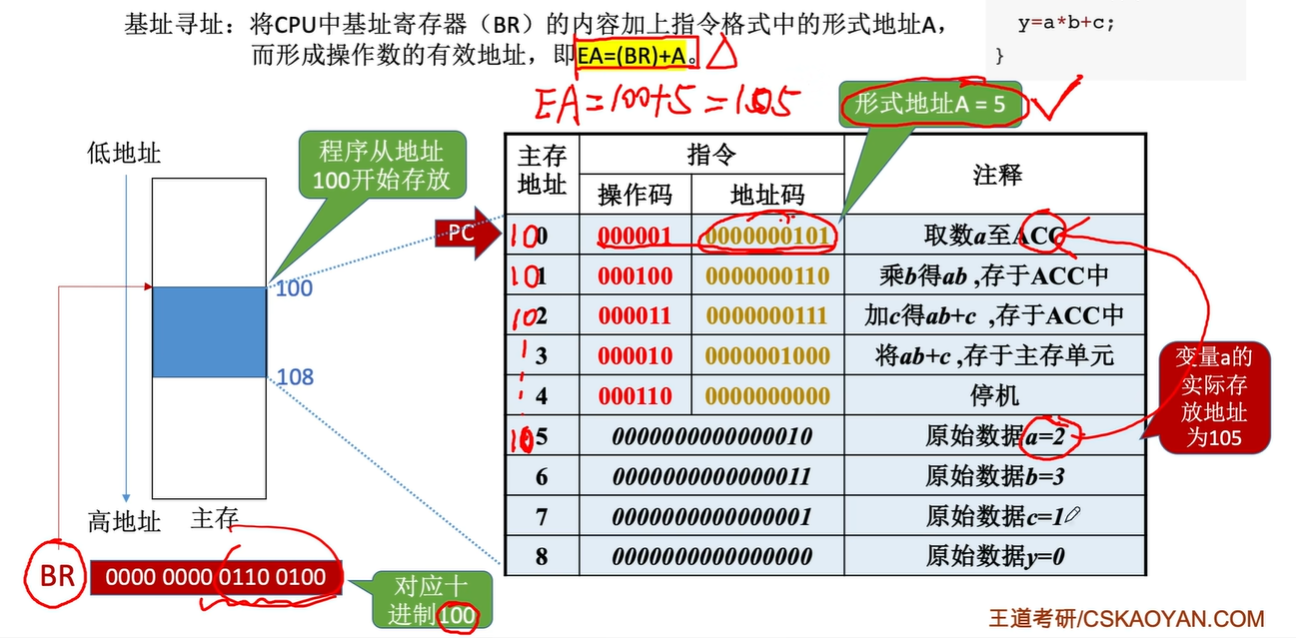
将CPU内部基址寄存器(BR)的内容(基地址)加上指令格式中的形式地址A形成操作数的有效地址
BR---base address register $$EA=A+(BR)$$
- 采用专用寄存器作为基址寄存器(隐式)
在计算机内专门设有一个基址寄存器BR,使用时用户不必明显指出该基址寄存器,只需要由指令的寻址特征位反映出基址寻址即可
- 采用通用寄存器作为基址寄存器(显式)
在一组通用寄存器中,由用户在指令中明确指出哪个寄存器用作基址寄存器,存放基地址 根据通用寄存器的总数判断用几个bit指明寄存器
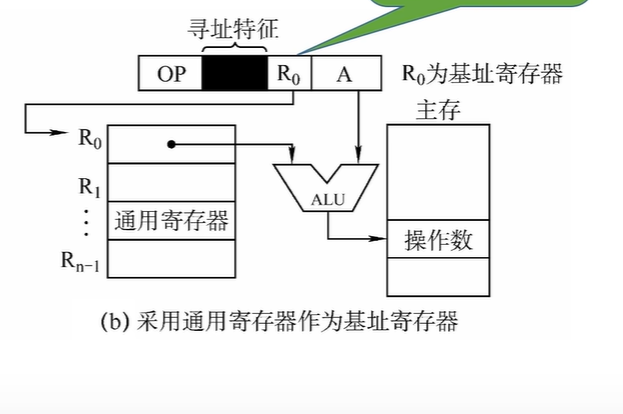
程序执行过程中Ri内容不变
优点:
- 可扩大寻址范围(基址寄存器的位数大于形式地址A的位数)
- 有利于多道程序以及可用于编制浮动程序(整个程序在内存里面浮动)
- 用户不必考虑自己的程序存于主存的哪一个空间区域,完全可由操作系统或管理程序根据主存的使用状况赋予基址寄存器内一个初始值(基地址),便可将用户程序的逻辑地址转换为内存的物理地址
- 在程序执行过程中,用户不知道自己的程序在主存的哪个空间,用户也不可修改基址寄存器的内容
- BR 由操作系统或管理程序确定(调入内存时),在程序的执行过程中 BR 内容不变
便于程序浮动(整段程序在内存中的浮动),可以从内存中任何一个地址作为起始地址往后存放,方便实现多道程序并发运行
注:
- 基址寄存器是面向操作系统的,其内容由操作系统或管理程序确定,在程序执行过程中,基址寄存器的内容不变(作为基地址),形式地址可变(作为偏移量)
- 当采用通用寄存器作为基址寄存器时,可由用户决定哪个寄存器作为基址寄存器,但其内容仍由操作系统决定
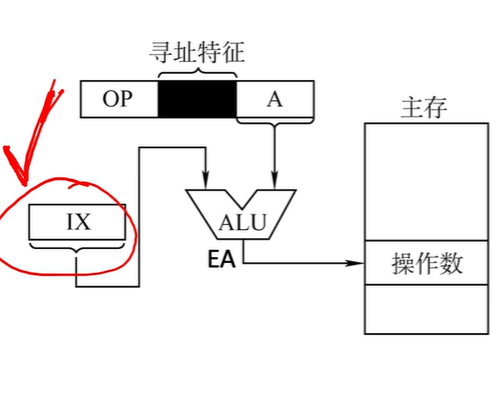
变址寻址
程序员自己决定从哪里作为起点
有效地址EA等于指令字中的形式地址A与变址寄存器IX的内容相加之和
IX--index register IX可为变址寄存器(专用)/通用寄存器 $$EA=A+(IX)$$
- 采用专用寄存器作为基址寄存器(隐式)
- 采用通用寄存器作为变址寄存器(显示) 优点:
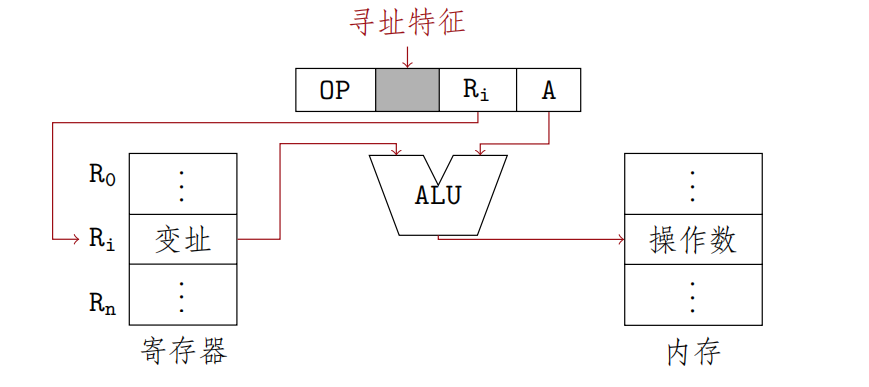
- 可扩大寻址范围
- IX的内容由用户指定
- 在程序的执行过程中,IX内容可变,形式地址A不变,便于处理数组问题
变址寻址VS基址寻址
相同点:
两者都可以有效扩大指令寻址处理范围
不同点:
- 两者使用方式不同
- 变址寻址方式:
- 指令提供基准量不变,R 提供修改量可变;适用于处理一维数组
- 变址寻址是面向用户的,在程序执行过程中,变址寄存器的内容可由用户改变(IX为偏移量),形式地址A不变(A基地址)
- 基址寻址方式:
- 基址寄存器的内容通常由操作系统或管理程序确定,在程序的执行过程中其值不变(BR为基地址),而指令字A可变(A为偏移量)
- 适用于扩大有限字长指令的访存空间
- 两者的应用目的不同
- 变址寻址方式面向用户,用于成批数据的连续便捷访问
- 基址寻址方式面向系统,主要用于为程序或数据分配存储空间,用来解决程序在实际主存中重定位问题(为程序分配存储空间)及扩大访存空间。
以一个例子说明变址寻址的作用
优点:
- 变址寻址主要用于处理数组问题,在数组处理过程中,可设定A为数组的首地址,不断改变变址寄存器IX的内容,便可很容易形成数组中任一数据的地址,特别适合编制循环程序
基址&变址复合寻址
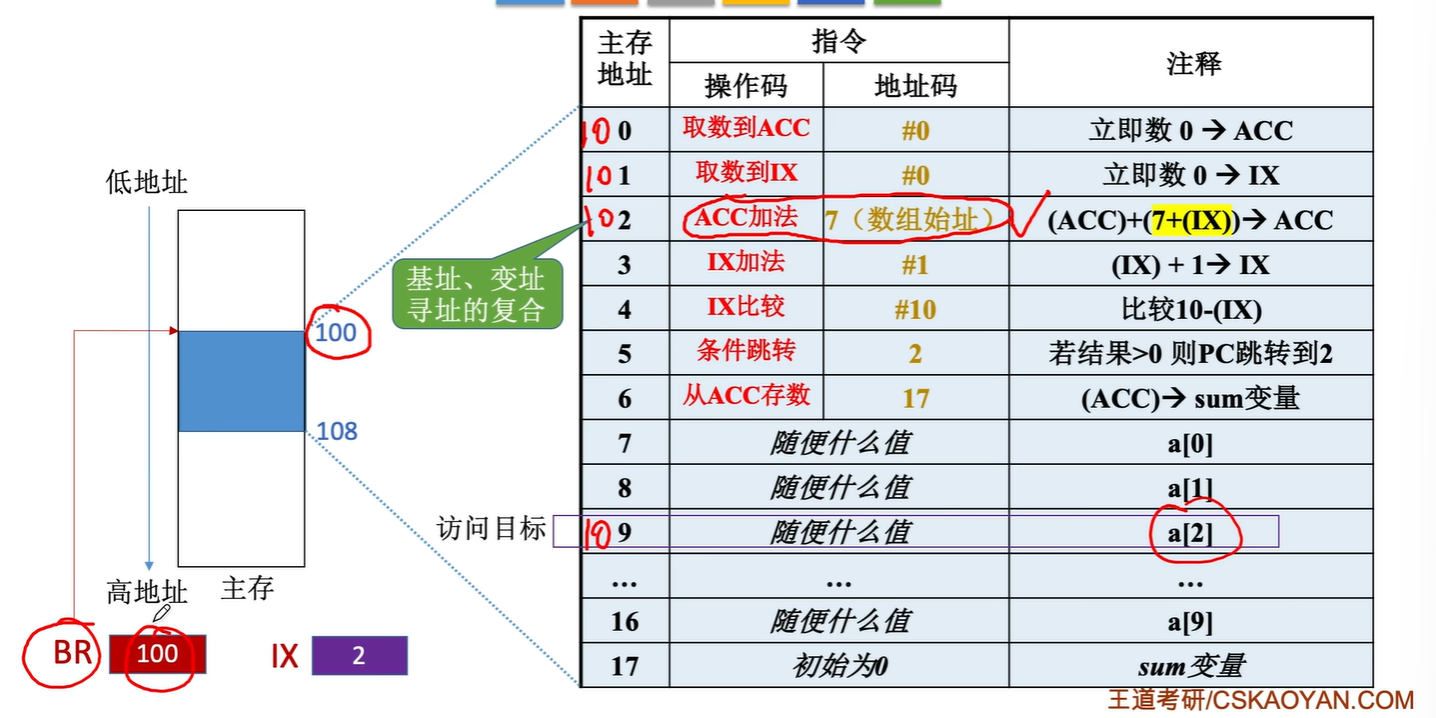
$$EA=A+(BR)+(IX)$$
重要思想:可以把每种寻址方式看为一个函数,将A->EA,只是映射规则不同,多种寻址方式复合相当于把不同的映射规则结合起来(复合函数)
相对寻址✔️
以程序计数器PC所指地址作为起点
相对寻址的有效地址是将程序计数器PC的内容与指令字中的形式地址A相加而成
$$EA=(PC)+A$$
A是
相对于PC所指地址的偏移量
,可正可负,
补码表示
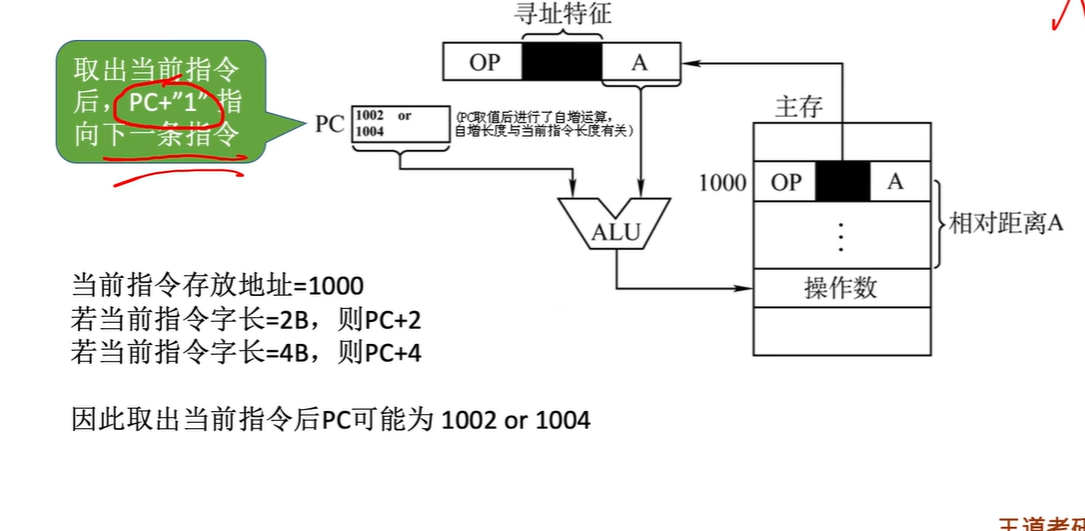
取出当前指令后,PC会指向下一条指令,相对寻址是相对于下一条指令的偏移
A 的位数决定操作数(或目标指令)的寻址范围
优点/作用:
初始:
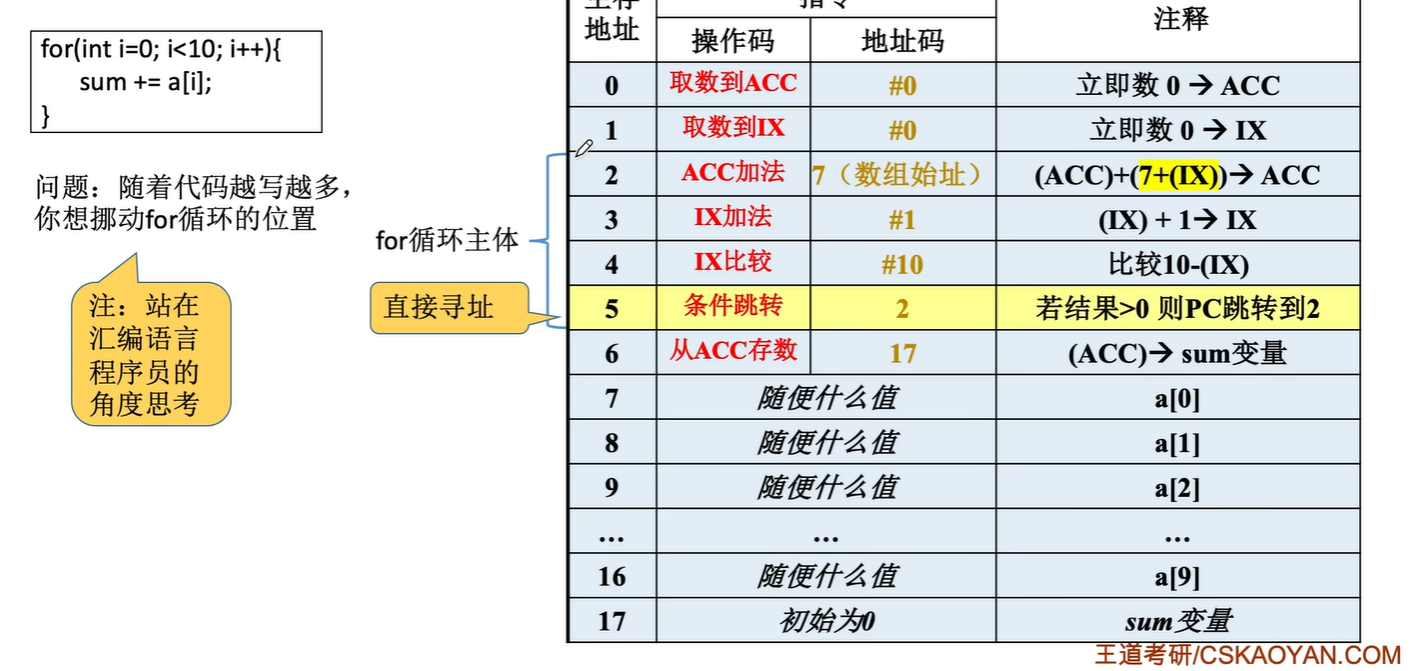
相对寻址后:
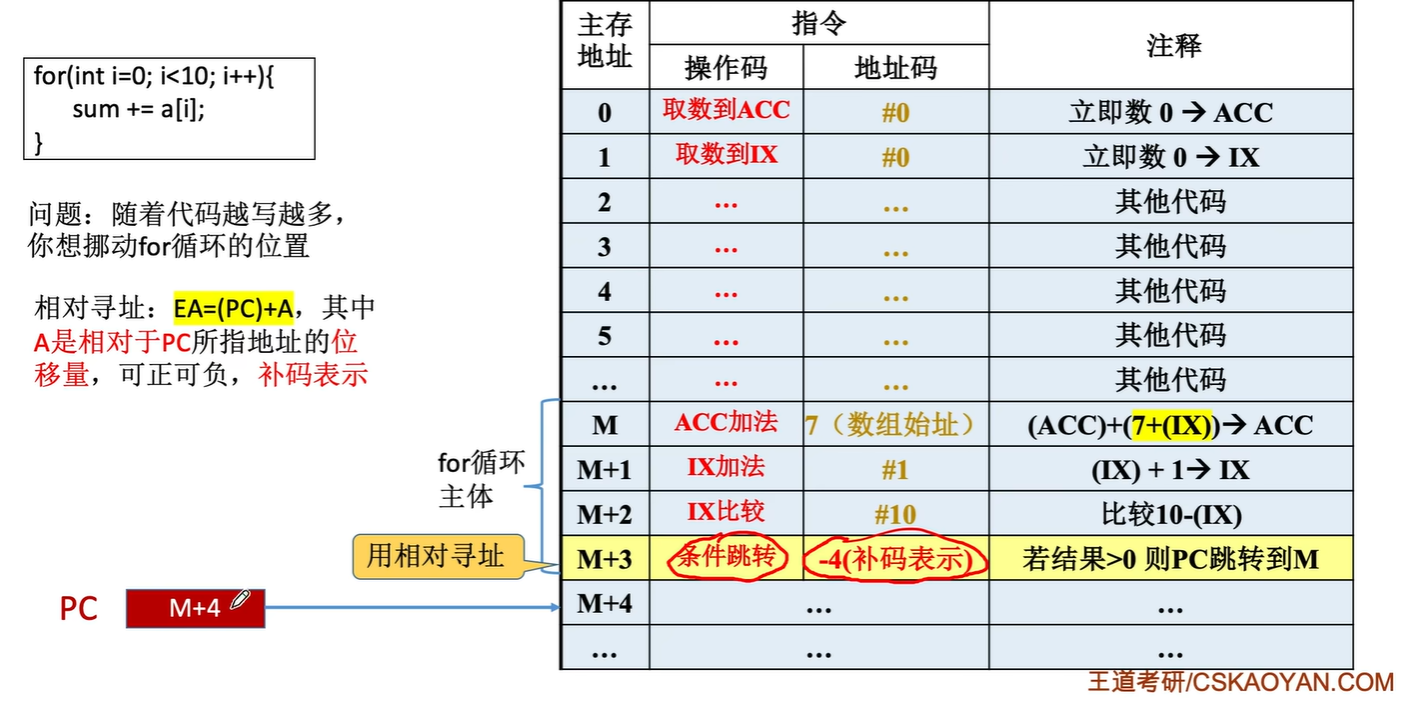
这段代码在程序内浮动时不用更改跳转指令的地址码
优点:操作数的地址不是固定的,它随着PC值的变化而变化,并且与指令地址间总是相差一个固定值,因此便于程序浮动(一段代码在程序内部的浮动)
相对寻址广泛应用于
转移指令
应用实例:

- PC 初始 = 2000H(指向 JMP 指令);
- 取 JMP 指令,PC 自动 + 2→2002H;
- 计算目标地址 = PC(2002H) + 位移量(06H)=2008H;
- 跳转到 2008H 执行目标指令
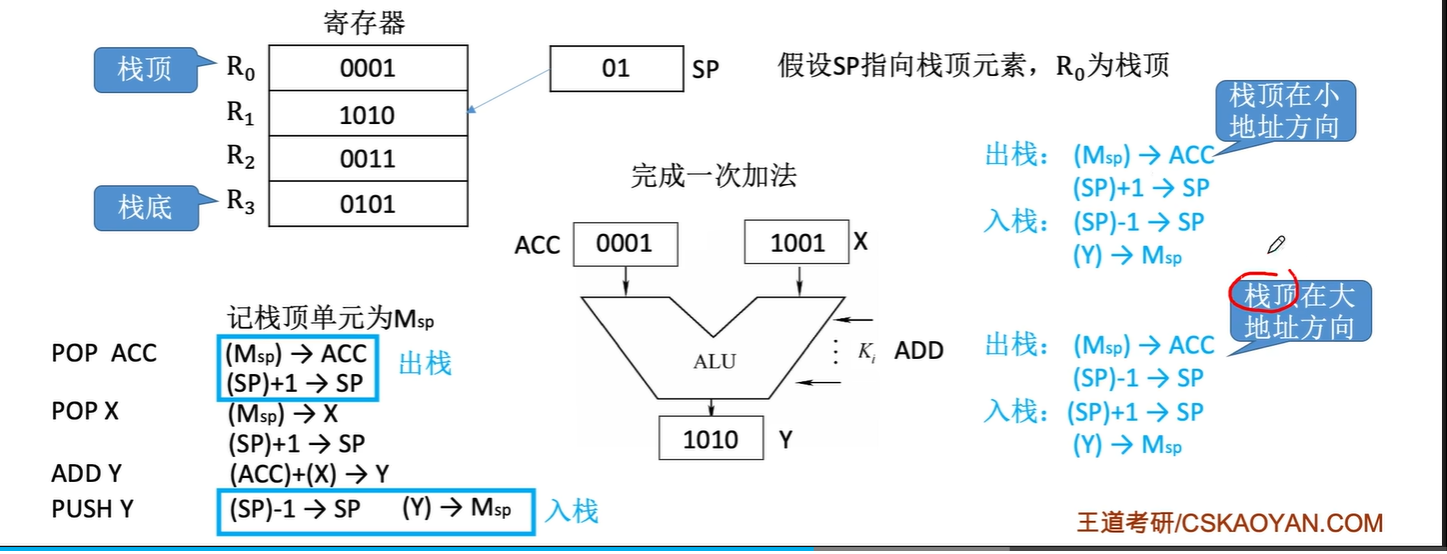
堆栈寻址
操作数存放在堆栈中,隐含使用堆栈指针(SP)作为操作数地址
SP---Stack Pointer 后进先出(LIFO),一个出入口,栈顶地址由SP指出
$$EA=(SP)$$
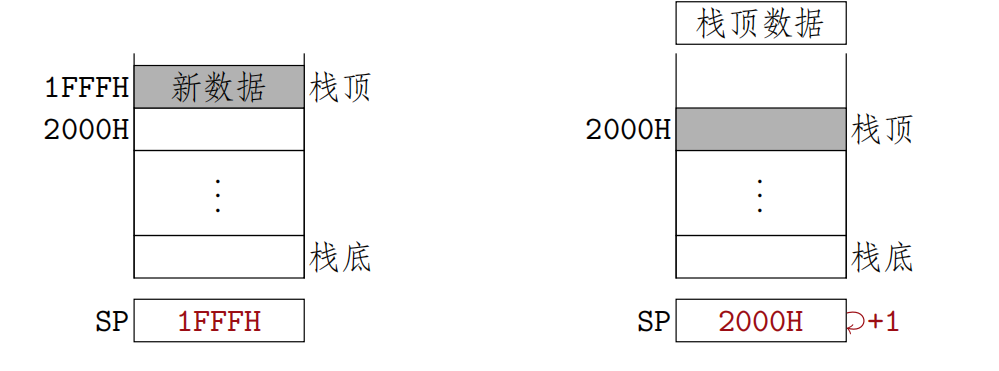
注意:
SP的修改方法与主存编址方法相关
按字编址:
进栈:(SP)-1->SP
出栈:(SP)+1->SP
按字节编址
(假设字长16位)
进栈:(SP)-2->SP
出栈:(SP)+2->SP
(假设字长32位)
进栈:(SP)-4->SP
出栈:(SP)+4->SP
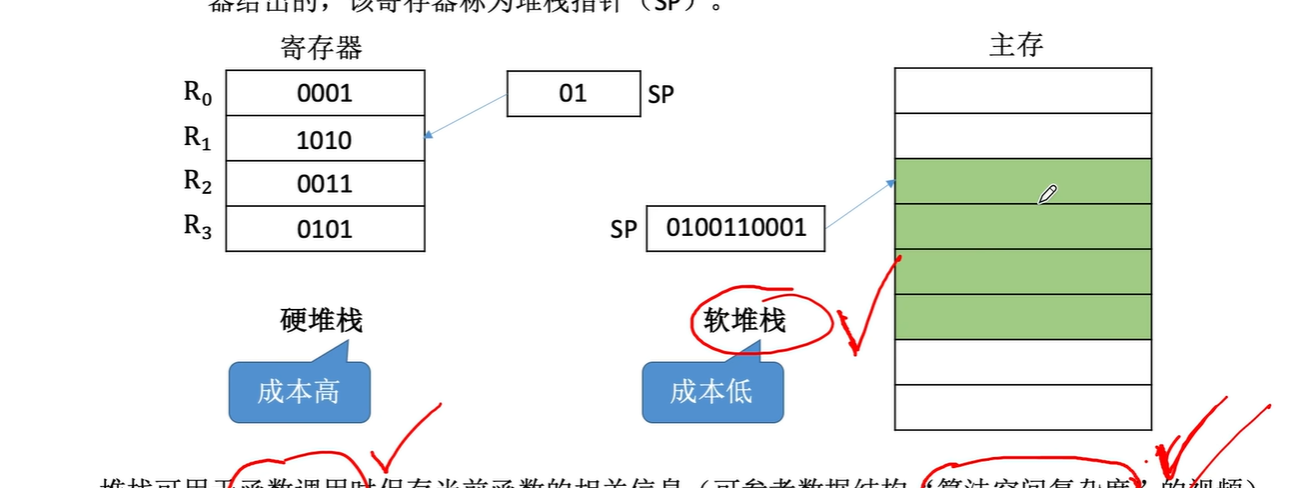
堆栈实现:
- 堆栈可以用寄存器数组(硬堆栈)来实现
- 也可利用主存的一部分空间(软堆栈)作堆栈
总结
指令格式
设计格式考虑因素
- 指令格式兼容性---向上兼容
- 操作类型 包括指令条数及操作的难易程度
- 数据类型 确定哪些数据类型可以参与操作
- 指令格式 指令字长、操作码位数、是否采用扩展操作码技术,地址码位数、地址个数、寻址方式类型
- 寻址方式 指令寻址、操作数寻址
- 寄存器个数 寄存器的多少直接影响指令的执行时间
指令格式设计✔️
RISC
RISC的产生和发展
- 概念: RISC(Reduced Instruction Set Computer):精简指令系统计算机 CISC(Complex Instruction Set Computer):复杂指令系统计算机
- 80-20定律,典型程序中80%的语句仅仅使用处理机中20%的指令,而且这些指令都是属于简单指令
- 执行频度高的简单指令,因复杂指令的存在,执行速度无法提高
- 能否用 20% 的简单指令组合替代不常用的 80% 的指令功能--RISC
程序的执行效率
程序总的执行时间 P = I × CPI × T,式中 I 是要执行的指令条数,CPI 是平均每条指令执行所需的时钟周期数/平均机器周期,T 是处理器时钟周期宽度/每个机器周期的执行时间
为提高程序的执行速度,采取的措施不同
- 不同点:CISC 是着眼减小 I,却付出了较大 CPI 的代价;RISC 是力图减小 CPI,却付出了较大 I 的代价。
- 共同点:二者都努力减小 T,提高处理器的时钟频率
RISC and CISC
RISC的主要特征
- 选用使用频度较高的一些简单指令,复杂指令的功能由简单指令来组合
- 指令长度固定、指令格式种类少、寻址方式少
- 只有 LOAD / STORE 指令访存,其余指令的操作都在寄存器内完成
- CPU中有多个通用寄存器
- 采用流水技术 一个时钟周期(均摊)内完成一条指令,采用超标量和超流水线技术,可使每条指令的平均执行时间小于一个时钟周期
- 采用组合逻辑实现控制器
- 采用优化的编译程序 商品化的RISC机通常不会是纯RISC机,故上述特点不是所有RISC机全部具备的
CISC的主要特征
- 系统指令复杂庞大,各种指令使用频度相差大
- 指令长度不固定、指令格式种类多、寻址方式多
- 访存指令不受限制
- CPU在设有专用寄存器
- 大多数指令需要多个时钟周期执行完毕
- 采用微指令实现控制器
- 难以优化编译生成高效的目标代码
RISC vs CISC
与CISC机相比,RISC机的主要优点可归纳为:
- 充分利用VLSI芯片的面积
- 提高计算机运算速度
- RISC机的指令数、寻址方式和指令格式种类较少,而且编码很有规律,指令译码更快
- 通用寄存器多,减少访存次数,加快运行速度
- 采用寄存器窗口重叠技术,程序嵌套时不必将寄存器内存保存到存储器中
- 采用组合逻辑控制,比采用微程序控制的CISC机的延迟少,缩短了CPU的周期
- 选用精简指令系统,适合流水线工作,大多数指令在一个周期内完成,便于实现指令流水
- RISC便于设计,可降低成本,提高可靠性
- 有效支持高级语言程序,有利于编译程序代码优化
- RISC不易实现指令系统兼容


